第 7 章 使用性能利器Redis
在现今互联网应用中,NoSQL已经广为应用,在互联网中起到加速系统的作用。有两种NoSQL使用最为广泛,那就是Redis和MongoDB
Redis是一种运行在内存的数据库,支持7种数据类型的存储。Redis是一个开源、使用ANSI C编写、遵循BSD协议、支持网络、可基于内存亦可持久化的日志型、键值数据库,并提供了多种语言的API。Redis是基于内存的、所以运行速度很快,大约是关系数据库几倍到几十倍的速度。如果我们将常用的数据存储在Redis中,用来代替关系数据库的查询访问,网站性能将得到大幅度提高
在现实中,查询数据要远远多于更新数据,一般一个网站的更新和查询比例是1:9到3:7,在查询比例比较大的网站使用Redis可以数倍地提高网站的性能。
除此之外,Redis还提供了简单的事务机制,通过事务机制可以有效保证在高并发的场景下数据的一致性。Redis本身数据类型比较少,命令功能也比较有限,运算能力一直不强,所以Redis在2.6版本之后增加了Lua语言的支持,这样Redis的运算能力就大大提高了,而且在Redis中Lua语言的执行是原子性的,也就是在Redis执行Lua时,不会被其他命令所打断,这样就保证了在高并发场景下的一致性
要使用Redis,需要先加入关于Redis的依赖,同样,SpringBoot也会为其提供starter ,然后允许我们通过配置文件application.properties进行配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>springboot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
|
7.1 spring-data-redis项目简介
先探讨在一个普通的Spring工程中如何使用Redis。这对于讨论SpringBoot中如何集成Redis很有帮助
7.1.1 spring-data-redis项目的设计
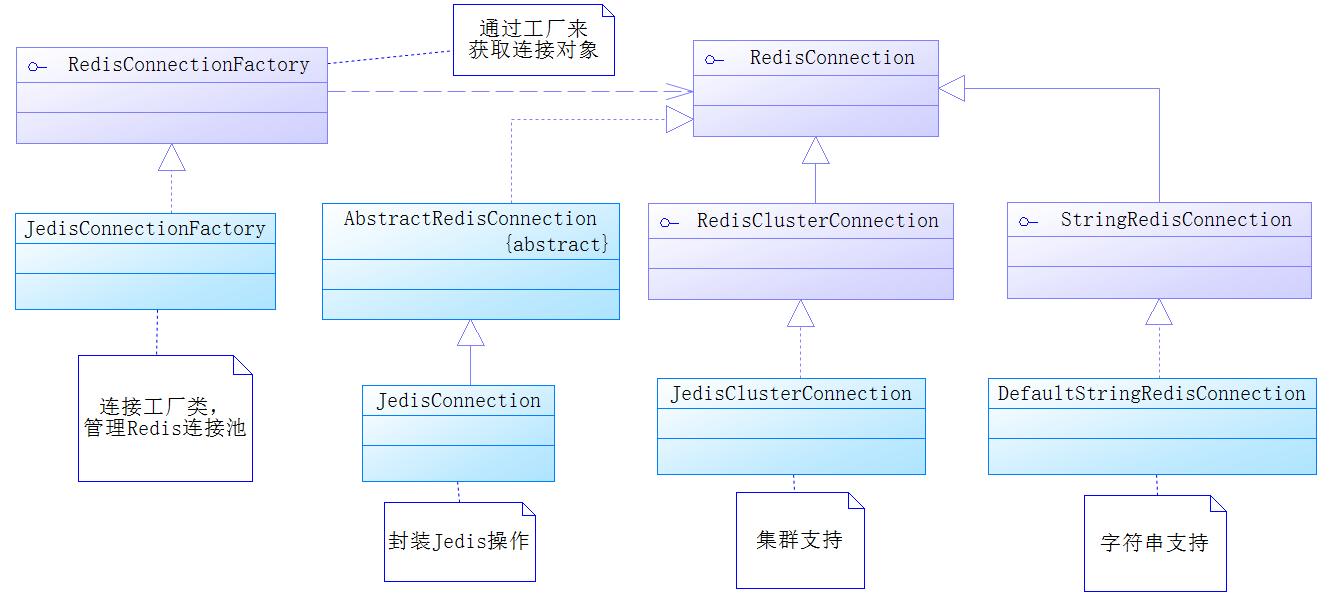
在Java中与Redis连接的驱动存在很多种,目前比较广泛使用的是Jedis,其他的还有Lettuce、Jredis和Srp
Spring提供了一个RedisConnectionFactory接口,通过它可以生成一个RedisConnection接口对象,
而RedisConnection接口对象是对Redis底层接口的封装。例如,本章使用的Jedis驱动,那么Spring
就会提供RedisConnection接口的实现类JedisConnection去封装原有的Jedis。类图如下
从上图看出
- 在
Spring中是通过RedisConnection接口操作Redis的,而RedisConnection则对原生的Jedis进行封装。要获取RedisConnection接口对象,是通过RedisConnectionFactory接口去生成的,所以第一步要配置的便是这个工厂了,而配置这个工厂主要是配置Redis的连接池,对于连接池可以限定其最大连接数、超时时间等属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Configuration
public class RedisConfig{
private RedisConnnectionFactory connectionFactory = null;
@Bean(name="RedisConnectionFactory")
public RedisConnectionFactory initRedisConnectionFactory(){
if(this.connectionFactory != null){
return this.connectionFactory;
}
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(30);
poolConfig.setMaxTatal(50);
poolConfig.setMaxWaitMillis(2000);
JedisConnectoionFactory connectionFactory = new JedisConnectionFactory(poolConfig);
}
}
|
7.1.2 RedisTemplate
RedisTemplate是个强大的类,首先它会自动从RedisConnectionFactory工厂获取连接,然后执行对应的Redis命令,在最后还会关闭Redis的连接,这些都被RedisTemplate封装了,所以开发者不用考虑Redis的闭合问题
1
2
3
4
5
6
7
8
| public class Main{
public static void main(String[] args){
ApplicationContext ctx = new AnnotationConfigApplicationContext(RedisConfig.class);
RedisTemplate redisTemplate = ctx.getBean(RedisTemplate.class);
redisTemplate.opsForValue().set("key1", "value1");
redisTemplate.opsForHash().put("hash", "field", "hvalue");
}
}
|
Redis是一种基于字符串存储的NoSQL,而Java是基于对象的语言,对象是无法存储到Redis中的,不过Java提供了序列化机制,只要类实现了java.io.Serializable接口,就代表类的对象能够进行序列化,通过
将类对象进行序列化就能够得到二进制字符串,这样Redis就可以将这些类对象以字符串进行存储。Java也可以将那些二进制字符串通过反序列化转为对象,通过这个原理,Spring提供了序列化器的机制,并且实现了几个序列化器,其设计如下图所示。
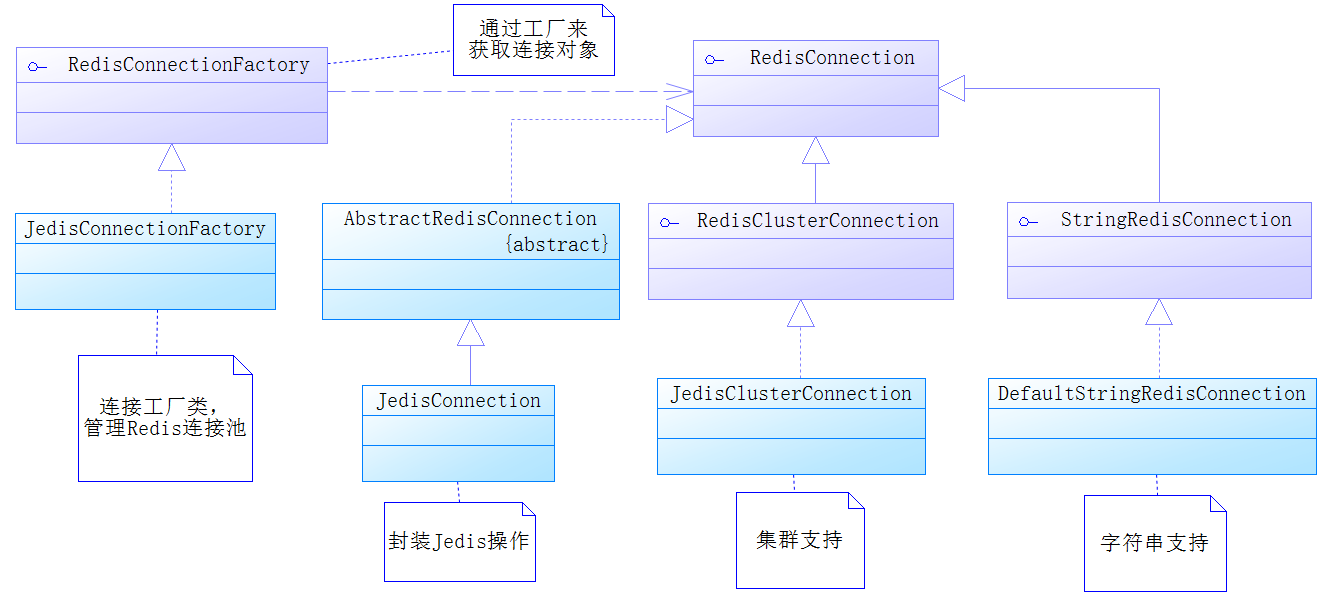
对于序列化器,Spring提供了RedisSerializer,它有两个方法。一个是serialize,它能把那些可以序列化的对象转化为二进制字符串;另一个是derializer,它能够通过反序列化把二进制字符串转换为Java对象,具体原理如下图所示
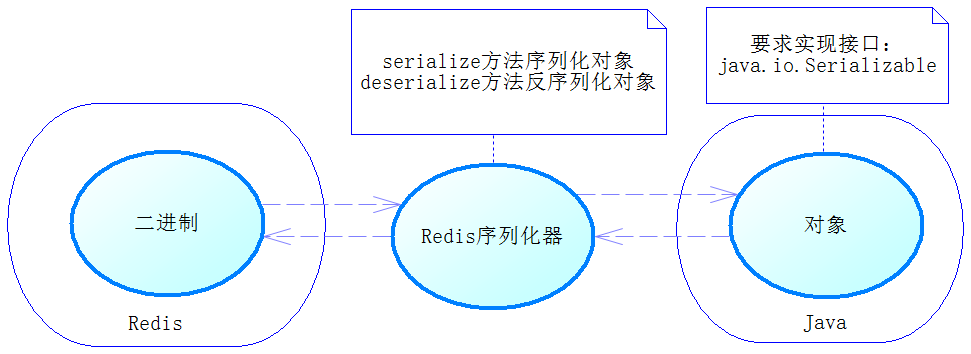
RedisTemplate提供了很多配置项,可以配置不同情况下的Serializer,例如redisTemplate.setKeySerializer(stringRedisSerializer);可以设置Redis的键序列化器
7.1.3 Spring对Redis数据类型的封装
Redis能够支持7种类型的数据结构,这7种类型是字符串、散列、列表、集合、有序集合、基数和地理位置。为此Spring针对每种数据结构都提供了对应的操作接口
1
2
3
4
5
6
|
redisTemplate.opsForList();
redisTemplate.opsForValue();
redisTemplate.opsForSet();
|
如果需要连续操作一个散列数据类型或列表多次,这时Spring也提供支持,它提供了对应的boundListOps接口,获得对应的操作接口后,就可以对某个键的数据进行多次操作
1
2
3
4
|
redisTemplate.boundHashOps("hash");
redisTemplate.boundListOps("list");
|
7.1.4 SessionCallback和RedisCallback接口
SessionCallback和RedisCallback接口的作用是让RedisTemplate进行回调,通过它们可以在同一条连接下执行多个Redis命令。其中,SessionCallback提供了良好的封装,对开发者比较友好
1
2
3
4
5
6
7
8
9
| public void useSessionCallback(RedisTemplate redisTemplate){
redisTemplate.execute(new SessionCallback(){
@Override
public Object exectute(RedisOprations ro) throws DataAccessException{
ro.opsForValue().set("key1", "value1");
ro.opsForHash().put("hash", "field", "hvalue");
}
})
}
|
7.2 在SpringBoot中配置和使用Redis
7.2.1 在SpringBoot中配置Redis
同样的,Springboot将Redis的配置集成到了application.properties文件中
1
2
3
4
5
6
7
8
| spring.redis.jedis.pool.min-idle=5
spring.redis.jedis.pool.max-active=5
spring.redis.jedis.pool.max-idle=10
spring.redis.jedis.pool.max-wait=2000
spring.redis.port=6379
spring.redis.host=192.168.11.128
spring.redis.password=123456
|
- 这样
SpringBoot的自动装配机制就会读取这些配置来生成有关Redis的操作对象,
- 它会自动生成
RedisConnectionFactory、RedisTemplate、StringRedisTemplate等常用的Redis对象
但是默认情况下,Redis会将一个经过序列化处理的特殊字符串存入服务器,这对我们跟踪并不友好,这时我们可以通过设置RedisTemplate的序列化器来解决
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @SpringBootApplication(scanBasePackages = "com.springboot.chapter7")
@MapperScan(basePackages = "com.springboot.chapter7", annotationClass = Repository.class)
@EnableCaching
public class Chapter7Application {
@PostConstruct
public void init() {
initRedisTemplate();
}
private void initRedisTemplate() {
RedisSerializer stringSerializer = redisTemplate.getStringSerializer();
redisTemplate.setKeySerializer(stringSerializer);
redisTemplate.setHashKeySerializer(stringSerializer);
}
....
}
|
- 这里利用
SpringBean生命周期注解@PostConstruct自定义后初始化方法。将RedisTemplate中的键序列化器改为了StringRedisSerializer,这样Redis服务器上得到的键和散列的field就都以字符串存储了
7.2.2 操作Redis数据类型
下面直接用代码来演示如何操作Redis数据类型(如字符串、散列、列表、集合和有序集合)
首先是操作字符串和散列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| @RequestMapping("/stringAndHash")
@ResponseBody
public Map<String, Object> testStringAndHash() {
redisTemplate.opsForValue().set("key1", "value1");
redisTemplate.opsForValue().set("int_key", "1");
stringRedisTemplate.opsForValue().set("int", "1");
stringRedisTemplate.opsForValue().increment("int", 1);
Jedis jedis = (Jedis) stringRedisTemplate.getConnectionFactory().getConnection().getNativeConnection();
jedis.decr("int");
Map<String, String> hash = new HashMap<String, String>();
hash.put("field1", "value1");
hash.put("field2", "value2");
stringRedisTemplate.opsForHash().putAll("hash", hash);
stringRedisTemplate.opsForHash().put("hash", "field3", "value3");
BoundHashOperations hashOps = stringRedisTemplate.boundHashOps("hash");
hashOps.delete("field1", "field2");
hashOps.put("filed4", "value5");
Map<String, Object> map = new HashMap<String, Object>();
map.put("success", true);
return map;
}
|
然后是操作列表,在Redis中,列表是一种链表结构,这就意味着查询性能不高,但增删节点的性能高
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| @RequestMapping("/list")
@ResponseBody
public Map<String, Object> testList() {
stringRedisTemplate.opsForList().leftPushAll("list1", "v2", "v4", "v6", "v8", "v10");
stringRedisTemplate.opsForList().rightPushAll("list2", "v1", "v2", "v3", "v4", "v5", "v6");
BoundListOperations listOps = stringRedisTemplate.boundListOps("list2");
Object result1 = listOps.rightPop();
Object result2 = listOps.index(1);
listOps.leftPush("v0");
Long size = listOps.size();
List elements = listOps.range(0, size - 2);
Map<String, Object> map = new HashMap<String, Object>();
map.put("success", true);
return map;
}
|
然后是集合,对于集合,在Redis中不允许成员重复,它在数据结构上是一个散列表的结构,所以对于它而言是无序的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @RequestMapping("/set")
@ResponseBody
public Map<String, Object> testSet() {
stringRedisTemplate.opsForSet().add("set1", "v1", "v1", "v2", "v3", "v4", "v5");
stringRedisTemplate.opsForSet().add("set2", "v2", "v4", "v6", "v8");
BoundSetOperations setOps = stringRedisTemplate.boundSetOps("set1");
setOps.add("v6", "v7");
setOps.remove("v1", "v7");
Set set1 = setOps.members();
Long size = setOps.size();
Set inter = setOps.intersect("set2");
setOps.intersectAndStore("set2", "inter");
Set diff = setOps.diff("set2");
setOps.diffAndStore("set2", "diff");
Set union = setOps.union("set2");
setOps.unionAndStore("set2", "union");
Map<String, Object> map = new HashMap<String, Object>();
map.put("success", true);
return map;
}
|
7.3 Redis的一些特殊用法
Redis除了操作那些数据类型的功能外,还能支持事务、流水线、发布订阅和Lua脚本等功能,这些也是Red is常用的功能。在高并发的场景中, 往往我们需要保证数据的一致性, 这时考虑使用Redis事务或者利用Redis执行Lua的原子性来达到数据一致性的目的,所以这里让我们对它们展开讨论。在需要大批量执行Redis命令的时候,我们可以使用流水线来执行命令,这样可以极大地提升Redis执行的速度。
7.3.1 使用Redis事务
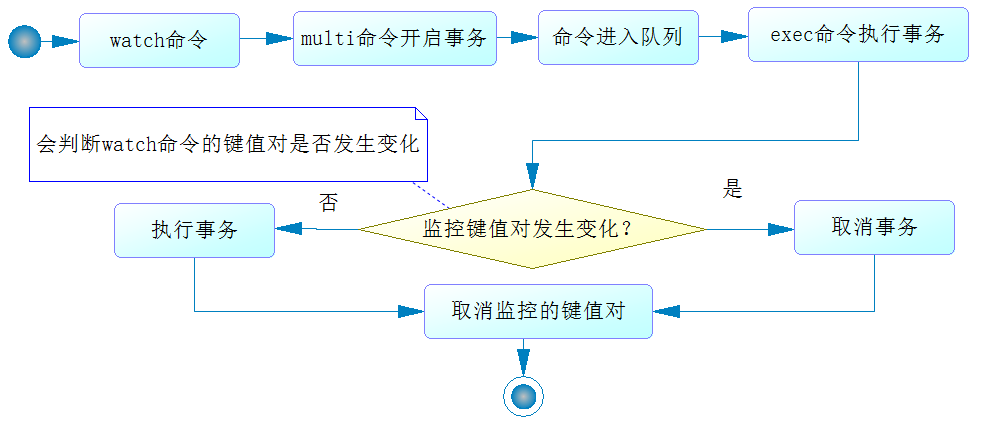
Redis是支持一定事务能力的NoSQL,在Redis中使用事务,常见的命令组合是watch...multi...exec,也就是要在一个Redis连接中执行多个命令
- 这时我们可以考虑使用
SessionCallback接口来达到这个目的
- 其中,
watch命令是可以监控Redis的一些键
multi命令是开始事务,开始事务后,该客户端的命令不会马上被执行,而是存放在一个队列里,在这时我们执行一些数据获取的命令,Redis也是不会马上执行的,而是把命令放到一个队列里,结果都是返回nullexec命令的意义在于执行事务,只是它在队列命令执行前会判断被watc 监控的Redis的键的数据是否发生过变化,如果它认为发生了变化,那么Redis就会取消事务,否则就会执行事务Redis在执行事务时,要么全部执行,要么全部不执行,而且不会被其他客户端打断,这样就保证了Redis事务下数据的一致性。- 事务执行的过程如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @RequestMapping("/multi")
@ResponseBody
public Map<String, Object> testMulti() {
redisTemplate.opsForValue().set("key1", "value1");
List list = (List) redisTemplate.execute((RedisOperations operations) -> {
operations.watch("key1");
operations.multi();
operations.opsForValue().set("key2", "value2");
operations.opsForValue().increment("key1", 1);
Object value2 = operations.opsForValue().get("key2");
System.out.println("命令在队列,所以value为null【" + value2 + "】");
return operations.exec();
});
System.out.println(list);
Map<String, Object> map = new HashMap<String, Object>();
map.put("success", true);
return map;
}
|
注意:对于Redis事务是先让命令进入队列,一开始它并没有检测这些命令是否能够成功,只有在exec命令执行的时候,才能发现错误,对于错误的命令Redis只是报出错误,而错误后面的命令依然被执行
7.3.2 使用Redis流水线
使用流水线后可以大幅度地在需要执行很多命令时提升Redis的性能。下面我们使用Redis流水线技术测试10 万次读写的功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @RequestMapping("/pipeline")
@ResponseBody
public Map<String, Object> testPipeline() {
Long start = System.currentTimeMillis();
List list = (List) redisTemplate.executePipelined((RedisOperations operations) -> {
for (int i = 1; i <= 100000; i++) {
operations.opsForValue().set("pipeline_" + i, "value_" + i);
String value = (String) operations.opsForValue().get("pipeline_" + i);
}
return null;
});
Long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "毫秒。");
Map<String, Object> map = new HashMap<String, Object>();
map.put("success", true);
return map;
}
|
- 10万次的读写基本在300-600ms
- 对于程序而言,这个
executePipelined最终将返回一个list,如果过多的命令执行返回的结果保存在这个List中,显然会造成内存消耗过大
- 与事务一样,使用流水线的过程中,所有的命令也只是进入队列而没有执行,所以执行的命令返回值也为空
7.3.3 使用Redis发布订阅
首先是Redis提供一个渠道,让消息能够发送到这个渠道上,而多个系统可以监听这个渠道,当一条消息发送到渠道,渠道就会通知它的监昕者,这些监听者会根据自己的需要去处理这个消息,于是我们就可以得到各种各样
的通知了。如下图所示
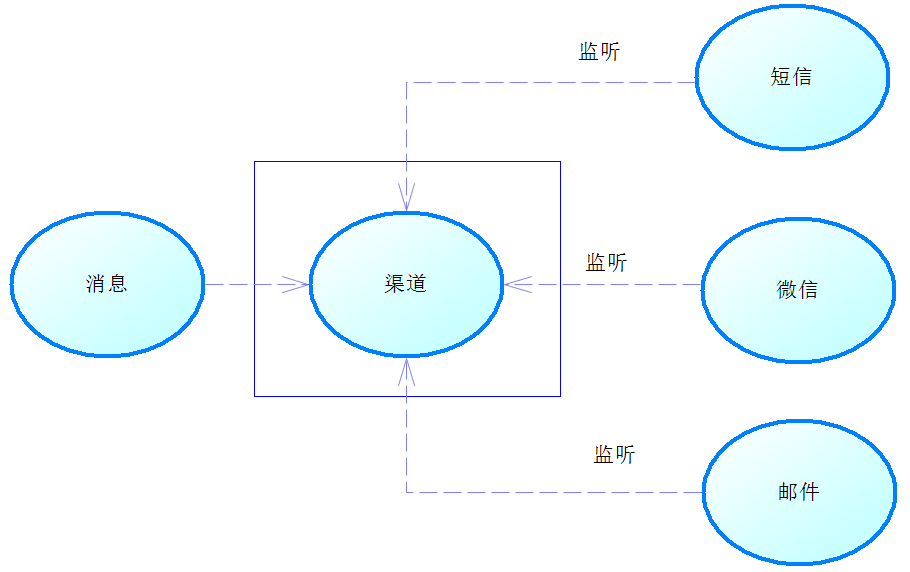
下面我们举个简单的例子,先定义一个消息监听器,然后在SpringBoot启动文件中配置其他信息,让系统可以监控Redis的消息
1
2
3
4
5
6
7
8
9
10
11
12
| @Component
public class RedisMessageListener implements MessageListener {
@Override
public void onMessage(Message message, byte[] pattern) {
String body = new String(message.getBody());
String topic = new String(pattern);
System.out.println(body);
System.out.println(topic);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@Bean
public ThreadPoolTaskScheduler initTaskScheduler() {
if (taskScheduler != null) {
return taskScheduler;
}
taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(20);
return taskScheduler;
}
@Bean
public RedisMessageListenerContainer initRedisContainer() {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setTaskExecutor(initTaskScheduler());
Topic topic = new ChannelTopic("topic1");
container.addMessageListener(redisMsgListener, topic);
return container;
}
|
- 这里我们定义了一个
Redis消息监听的容器RedisMessageListenerContainer
- 然年后在容器中设置了连接工厂、任务池
- 定义了接收
topic1渠道的消息,这样就可以监听Redis关于topic1渠道的消息
7.3.4 使用Lua脚本
略
7.4 使用Spring缓存注解操作Redis
为了进一步简化Redis的使用,Spring还提供了缓存注解,使用这些注解可以有效简化编程过程
7.4.1 缓存管理器和缓存的启用
spring在使用缓存注解前,需要配置缓存管理器,缓存管理器将提供一些重要的信息,如缓存类型、超时时间等。Spring可以支持多种缓存的使用,而使用Redis,主要就是以使用类RedisCacheManager为主。
1
2
3
4
5
6
| spring.cache.type=REDIS #定义缓存类型
spring.cache.cache-names=redisCache #定义缓存名称
spring.cache.redis.cache-null-values=true #是否允许Redis缓存空值
spring.cache.redis.key-prefix=xxx #Redis的键前缀
spring.cache.redis.time-to-live=0ms #缓存超时时间戳,配置为0则不设置超时时间
spring.cache.redis.use-key-prefix=true #是否启用Redis的键前缀
|
此外,我们还需要在SpringBoot启动类上加入驱动缓存注解@EnableCaching这样就可以驱动Spring缓存机制工作了
1
2
3
4
5
6
7
8
| @SpringBootApplication(scanBasePackages = "com.springboot.chapter7")
@MapperScan(basePackages = "com.springboot.chapter7", annotationClass = Repository.class)
@EnableCaching
public class Chapter7Application {
}
|
7.4.2 开发缓存注解
下面举一个处理用户的Service的例子,来说明如何以注解的方式使用Redis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao = null;
@Override
@Transactional
@CachePut(value = "redisCache", key = "'redis_user_'+#result.id")
public User insertUser(User user) {
userDao.insertUser(user);
return user;
}
@Override
@Transactional
@Cacheable(value = "redisCache", key = "'redis_user_'+#id")
public User getUser(Long id) {
return userDao.getUser(id);
}
@Override
@Transactional
@CachePut(value = "redisCache", condition = "#result != 'null'", key = "'redis_user_'+#id")
public User updateUserName(Long id, String userName) {
User user = this.getUser(id);
if (user == null) {
return null;
}
user.setUserName(userName);
userDao.updateUser(user);
return user;
}
@Override
@Transactional
public List<User> findUsers(String userName, String note) {
return userDao.findUsers(userName, note);
}
@Override
@Transactional
@CacheEvict(value = "redisCache", key = "'redis_user_'+#id", beforeInvocation = false)
public int deleteUser(Long id) {
return userDao.deleteUser(id);
}
}
|
@CachePut表示将方法结果返回存放到缓存中@Cacheable表示先从缓存中通过定义的键查询,如果可以查询到数据,则返回,否则执行该方法,返回数据,并将返回结果保存到缓存中@CacheEvict通过定义的键移除缓存
7.4.3 测试缓存注解
略
7.4.4 缓存注解自调用失效问题
如7.4.2中的例子,因为Spring的缓存机制也是基于SpringAOP的原理,而在Spring中AOP是通过动态代理技术来实现的,这里的updateUserName方法调用getUser方法是类内部的自调用,并不存在代理对象的调用,这样便不会出现AOP,也就不会使用到标注在getUser上的缓存注解去获取缓存的值了
7.4.5 缓存脏数据说明
使用缓存很可能出现脏数据问题,如下所示

T6时刻,因为使用了key_2为键缓存数据,所以会致使动作l以key_ 1为键的缓存数据为脏数据。这样使用key_l为键读取时,就只能获取脏数据了,这只是存在脏数据的可能性之一,还可能存在别的可能对于数据的读和写采取的策略是不一样的。
对于数据的读操作,一般而言是允许不是实时数据,如一些电商网站还存在一些排名榜单,它会存在延迟,存在脏数据是允许的。但是如果一个脏数据始终存在就说不通了,这样会造成数据失真比较严重。一般对于查询而言,我们可以规定一个时间,让缓存失效,对于那些要求实时性比较高的数据,我们可以把缓存时间设置得更少一些,这样就会更加频繁地刷新缓存
对于数据的写操作,往往采取的策略就完全不一样,需要我们谨慎一些,一般会认为缓存不可信, 所以会考虑从数据库中先读取最新数据,然后再更新数据,以避免将缓存的脏数据写入数据库中,导致出现业务问题。
