
第8章 读写外部系统
数据可以存储在许多不同的系统中,比如文件系统、对象存储、关系数据库系统、键值存储、搜索索引(search indexes)、事件日志、消息队列等等。每一类系统都是为特定的访问模式而设计的,有各自擅长的领域。因此,当今的数据基础设施常常由许多不同种类的存储系统组成。
数据处理系统(如Apache Flink)通常不包含自己的存储层,而是依赖于外部存储系统来摄取和持久存储数据。因此,对于像Flink这样的数据处理系统来说,提供一套齐全的从外部系统读取数据和向外部系统写入数据的连接器库以及提供一套能够自定义连接器的API是很重要的。
8.1 应用的一致性保障
要保障应用的一致性除了依赖于Flink的检查点机制之外,还需要数据源和数据汇连接器提供一些其他的特性与检查点机制配合。换句话说,应用的一致性保障依赖于三方面
- 检查点机制
- 数据源连接器提供的读取位置重置
- 数据汇连接器提供的幂等性写或者事务性写
8.1.1 数据源连接器提供的一致性保障
为了为应用程序提供精确一次的状态一致性保障,应用的每个数据源连接器都需要能够将其读取位置重置。
- 当生成检查点时,数据源算子将存储其当前读取位置标识符并在需要恢复时利用远程存储来恢复这些位置标识符。
- 支持读取位置重置的例子有:
- 基于文件的数据源(会存储文件字节流的读取偏置)
- Kafka数据源(会存储消费主题分区的读取偏置)
- 如果数据源连接器 无法存储和重置读取位置,那么此应用只能提供最多一次保证。
读取位置重置再加上检查点机制,就可以提供至少一次的一致性保障,如果还需要精确一次的一致性保障,那我们就需要数据汇连接器再提供一些其他的特性。
8.1.2 数据汇连接器提供的一致性保障
8.1.2.1 幂等性写
幂等性是指:对于同一个系统,在同样条件下,一次请求和重复多次请求 对资源的影响是一致的,就称该操作为幂等的。
生活中的幂等操作
- 博客系统同一个用户对同一个文章点赞,即使这人单身30年手速疯狂按点赞,那么实际上也只能给这个文章 +1 赞
- 在微信支付的时候,一笔订单应当只能扣一次钱,那么无论是网络问题或者bug等而重新付款,都只应该扣一次钱
在Flink中我们主要在数据汇连接器上应用幂等性的概念来提供端到端精确一次的一致性保障。
举个简单的例子,假设我们要统计多个传感器的最高温度并且使用一个键值存储作为数据汇写入的外部系统。那么我们只要在数据汇算子中对键值存储系统进行upsert操作(看看key是否存在,存在就update,不存在就insert)就可以保证幂等性。因为对于一个传感器来说,多次插入数据,最终都只会产生一个k-v对。
再具体点:
- 经过计算,数据汇发出一条
("sensor_1", 100.0),然后这条记录被写入了键值存储系统。- 但是写入之后,发生了故障,系统恢复故障并重置到上一个检查点,经过重放,数据汇又发出了一条
("sensor_1", 100.0),然后这条记录也被写入了键值存储系统。- 但是幸运的是,因为upsert操作是幂等的,插入两条
("sensor_1", 100.0)与插入一条("sensor_1", 100.0)对键值存储系统来说,影响是一样的。- 借此,我们成功保证了精确一次的一致性
8.1.2.2 事务性写
第二种完全实现端到端精确一次的一致性方法是事务性写。这里的基本思想是只将那些位于上一个成功检查点之前的事件发送给外部系统。
相比于幂等性写,事务性写延迟更高,但是不会重复发送事件给外部系统,因此不会出现恢复过程中的不一致。
Flink中有两种事务性数据汇连接器
- write-ahead-log (WAL)数据汇
- 两阶段提交(2PC)数据汇
8.1.2.2.1 WAL
- WAL数据汇将所有事件 先写入到算子状态,并在接收到检查点完成的通知后再将它们发送给外部系统。
- WAL通用性很好,可以应对任何类型的外部系统(因为状态是缓存在算子状态中的)
- 但是,它不能提供100%的一致性保证,并且增加了应用的状态大小。
8.1.2.2.2 2PC
- 2PC数据汇需要外部系统提供对事务的支持。
- 对于每个检查点,2PC数据汇启动外部系统的一个事务,并将所有接收到的记录写入到该事务。
- 当它收到检查点完成的通知时,它提交事务。
- 2PC协议依赖于Flink现有的检查点机制。
- 检查点分隔符可以作为启动新事务的指令
- 所有算子任务关于其单个检查点成功向JobManager发通知可以看作是它们的提交投票
- 而来自JobManager的检查点成功的消息是提交事务的指令。
下表展示了不同类型的数据源和数据汇连接器的搭配,能提供的一致性保障
| \ | 不可重置数据源 | 可重置数据源 |
|---|---|---|
| 任意数据汇 | 至多一次 | 至少一次 |
| 幂等性数据汇 | 至多一次 | 精确一次(故障恢复过程中,会出现临时的不一致,故障恢复后,就恢复精确一次) |
| WAL数据汇 | 至多一次 | 至少一次(无法100%提供精确一次保障) |
| 2PC数据汇 | 至多一次 | 精确一次 |
8.2 内置连接器
Apache Flink提供了各种内置连接器来从各种外部系统读取数据和向各种外部系统写入数据。
- 像Kafka这样的消息队列和事件日志是常见的外部源
- 而消息队列、文件系统、键值系统、数据库系统是常见的外部汇
为了在应用中使用这些连接器,你需要将相应的依赖项添加到项目的构建文件中。
8.2.1 Apache Kafka 数据源连接器
首先介绍Kafka
- Apache Kafka是一个分布式流处理平台。
- 它的核心是一个分布式的发布-订阅消息系统,该系统被广泛用于摄入(ingest)和分发(distribute)事件流。
- Kafka将事件流组织为所谓的主题。
- 主题是一种事件日志(event log),它保证事件顺序。
- 我们可以将主题划分为多个分区,这些分区分布在一个集群中。
- 有序保证仅限于单个分区—kafka在从不同分区读取时不提供有序保证。Kafka在分区中读取位置称为偏移量(offset)。
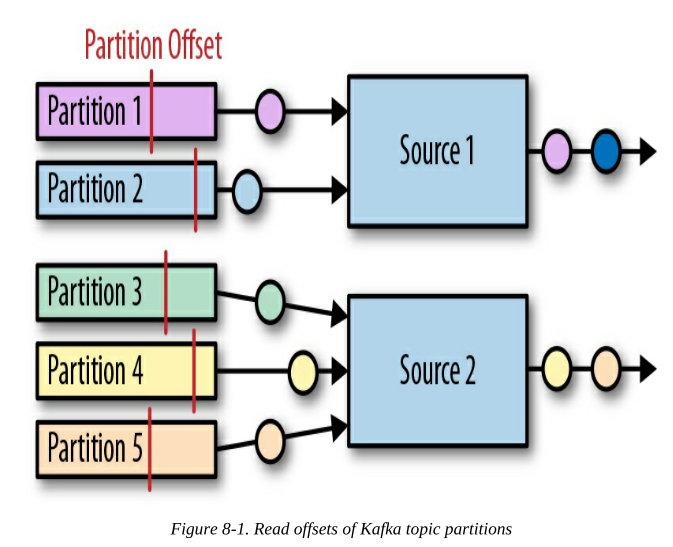
Flink Kafka连接器可以并行读取事件流。
- 每个数据源算子任务可以从一个或多个分区读取。
- 任务 跟踪每个分区的当前读取偏移,并将偏置记录到其检查点数据中。
- 从故障中恢复时,偏移量被取出,任务继续从检查点偏移量读取事件流。
图8-1显示了为数据源算子任务分配分区的情况
下面看看如何创建一个Kafka数据源连接器
1 | val properties = new Properties() |
8.2.2 Apache Kafka 数据汇连接器
下面看看如何创建一个Kafka数据汇连接器
1 | val stream: DataStream[String] = ... |
8.2.2.1 Kafka数据汇的至少一次保障
Kafka数据汇在以下条件都满足的情况下提供至少一次的保证:
- Flink的检查点机制是开启的
- 所有数据源都是可重置的
- 如果写入未成功,数据汇连接器要抛出异常(这样可以让应用失败然后恢复)
- 在提交检查点之前,数据汇连接器要等待 Kafka 确认传输中的记录全部写入完毕。
8.2.2.2 Kafka数据汇的精确一次保障
Kafka支持事务性写,因此Flink的Kafka数据汇也能够提供精确一次的一致性保障。但精确一次保障同样需要应用满足8.2.2.1中的几个条件。
FlinkKafkaProducer提供了一个带有Semantic参数的构造函数,该构造函数可以控制数据汇提供的一致性保证级别,该配置的选项如下:
- Semantic.NONE:不提供任何一致性保证——记录可能会丢失或多次写入
- Semantic.AT_LEAST_ONCE:至少一次保证,记录不会丢失,但可能会重复。这是默认设置。
- Semantic.EXACTLY_ONCE:精确一次保证
8.2.2.3 CUSTOM PARTITIONING AND WRITING MESSAGE TIMESTAMPS
当向Kafka主题写入消息时,Flink Kafka数据源算子任务可以选择要写入主题的哪个分区。
- 你可以通过提供一个自定义的FlinkKafkaPartitioner来控制数据到主题分区的路由方式。
- 默认情况下,Flink将每个任务映射到一个Kafka分区。也就是说,由同一个任务发出的所有记录都写入到同一个分区。
通过调用数据汇上的setWriteTimestampToKafka(true),可以将记录的事件时间戳写入Kafka。
8.2.3 文件系统数据源连接器
文件系统通常用于以高性价比的方式存储大量数据。在大数据架构中,它们经常作为批处理应用程序的数据源和数据接收器。通过与高级文件格式(如Apache Parquet或Apache ORC)相结合,文件系统可以有效地为分析查询引擎(如Apache Hive、Apache Impala或Presto)服务。因此,文件系统通常用于**“连接”** 流处理应用和批处理应用。
Apache Flink内置了一个文件数据源连接器,它支持重置,并可以将文件中的数据作为数据流输入到应用中。此外,它还支持多种类型的文件系统,比如:本地文件系统、HDFS、S3等等。
文件系统数据源的创建方法如下
1 | val lineReader = new TextInputFormat(null) |
FileProcessingMode是目标路径的读取模式,有如下两种选择
- 在PROCESS_ONCE模式下,当作业启动并读取所有匹配的文件时,读取路径只被扫描一次。
- 在PROCESS_CONTINUOUSLY中,会定期扫描路径(在初始扫描之后),并持续读取新的和修改的文件。
8.2.4 文件系统数据汇连接器
将数据流写入文件是一种常见的需求。由于大多数应用只能在文件最终完成后读取文件,并且流应用运行时间很长,因此数据汇连接器通常会将输出分块存储到多个文件中。
当满足如下条件时,文件系统数据汇连接器可以为应用提供端到端的精确一次保障:
- 应用开启检查点机制
- 所有数据源都支持重置
下面看看如何创建一个文件系统数据汇连接器
1 | val input: DataStream[String] = … |
数据汇的文件分块机制分为三级:
- 数据流被划分为多个桶
- 每条记录都会被分配到一个桶中
- 每个桶都对应基础路径下的一个子路径
- 如果没有显式指定,Flink根据事件的处理时间将记录分配给每小时一个的桶中。
- 每个桶中包含多个part文件
- 每个bucket路径下包含多个part文件
- 这些part文件由数据汇算子的多个任务并发地写入。
- 此外,每个并行任务也将其输出分割成多个part文件。
- 这些分块文件路径:
[base-path]/[bucket-path]/part-[task-idx]-[id] - 例如,基础路径为
/johndoe/demo/,分块文件前缀为part,则路径/johndoe/demo/2018-07-22-17/part-4-8指向2018年7月22日下午5点这个桶内(/2018-07-22-17/),由第4个接收任务的写入的第8个文件(/part-4-8)。
StreamingFileSink提供了两种文件编码模式:行编码和批量编码。
- 在行编码模式中,每个记录都被单独编码然后写入到一个part文件中。我们调用
StreamingFileSink.forRowFormat()方法就是使用行编码模式 - 在批量编码模式中,多条记录被一起编码然后写入到一个part文件中。我们调用
StreamingFileSink.forBulkFormat()方法就是使用批量编码模式
8.2.5 Apache Cassandra 数据汇连接器
Apache Cassandra是一种可伸缩的、高可用的列式存储数据库系统。
- Cassandra将数据集建模为由多个类型的列所组成的行表(Cassandra models datasets as tables of rows that consist of multiple typed columns.)。
- 可以将一个或多个列定义为(复合)主键。每一行都可以通过其主键唯一地标识。
- Cassandra提供了Cassandra查询语言(CQL),这是一种类似sql的语言,用于读写记录以及创建、修改和删除数据库对象。
Flink的Cassandra连接器是可以提供精确一次保障的
-
Cassandra的数据模型基于主键(K-V式的),所有写到Cassandra的操作都使用upsert语义(有就update,没有就insert)。因此,基于Cassandra的数据汇写入操作是幂等的
-
与此同时,为了避免故障恢复期间的短暂不一致,Cassandra连接器可以通过配置开启WAL机制。
下面是例子
首先定义一个Cassandra表结构
1 | // 创建键空间 |
下面先展示如何将tuple、case class等类型写入Cassandra
1 | val readings: DataStream[(String, Float)] = ??? |
- 写入tuple、case class时需要指定CQL INSERT查询。
- 数据汇将查询注册为PreparedStatement,并将tuple或case class的字段转换为PreparedStatement中的参数。
- 字段 根据其位置映射到参数;第一个值被转换为第一个参数。
下面再展示如何将POJO写入Cassandra
1 | val readings: DataStream[SensorReading] = ??? |
1 | (keyspace = "example", name = "sensors") |
- 需要通过注解来映射POJO字段到Cassandra列
8.3 实现自定义数据源函数
DataStream API提供了两个接口来自定义数据源连接器,这两个接口都有相应的RichFunction抽象类:
- SourceFunction用于非并行的数据源连接器
- ParallelSourceFunction用于支持同时运行多个任务的数据源连接器
这两个接口中的方法一样,如下所示
| 签名 | 描述 |
|---|---|
void run(SourceContext<T> ctx) |
run()方法负责执行实际的事件读入工作。Flink会开一个专门的线程,然后在这个线程中调用run()方法一次。 |
void cancel() |
负责终止事件读入 |
下面举一个简单的例子,它创建一个简单的从0数到Long.maxValue的自定义数据源函数
1 | class CountSource extends SourceFunction[Long] { |
8.3.1 可重置的数据源函数
Flink只能在数据源连接器支持重放输入数据时才能提供各种一致性保证。
- 如果外部源系统提供了读取偏移量和重置偏移量的API,则数据源算子可以重放输入数据。
- 比如:文件系统。它提供文件流偏移量,它还提供将文件流移动到特定位置的seek方法,
- 再比如:Apache Kafka,它为主题的每个分区提供偏移量,并可以设置分区的读取位置。
- 一个反例是web socket,它从网络套接字读取数据,并且立即丢弃交付的数据,因此它不支持重放
支持重放的数据源算子要与检查点机制 配合
- 在生成检查点时,数据源算子要持久化所有当前读取偏移量。
- 故障恢复时,数据源算子要从最新的检查点恢复偏移量到本地。
如果数据源算子要支持重放,则需要实现CheckpointedFunction接口,具体例子如下
1 | // 可重置的SourceFunction |
8.3.2 数据源函数、时间戳及水位线
DataStream API提供了两种方式来分配时间戳和生成水位线。
- 时间戳和水位线可以由专用的
TimestampAssigner分配和生成 - 时间戳和水位线也可以由
SourceFunction分配和生成。
SourceFunction的SourceContext对象提供了分配水位线和时间戳的方法
1 |
|
注意:当单个数据源算子任务 并行处理 多个partition时,使用SourceFunction来生成水位线比使用单独的TimestampAssigner更好,具体原因略、
8.4 实现自定义数据汇函数
DataStream API提供了SinkFunction接口来自定义数据汇函数。SinkFunction接口中只有一个方法:
1 | void invoke(IN value, Context, ctx) |
下面示例显示了一个简单的SinkFunction,它将传感器读数写入套接字。
1 | // write the sensor readings to a socket |
为了实现端到端精确一次保障,数据汇连接器需要幂等或支持事务,下面我们看看这两种
8.4.1 幂等性数据汇连接器
如果外部汇系统满足如下两个条件,SinkFunction接口就足以实现幂等性数据汇连接器
- 结果数据具有固定的键,可以在该键上执行幂等更新。
- 对于计算每个传感器和每分钟的平均温度的应用程序,固定的键可以是传感器的ID和每分钟的时间戳。
- 外部系统支持按键更新,例如关系数据库系统可以按照主键更新(update … where sensor_id = xxx)或键值存储可以按照key更新
下面的例子演示了如何实现和使用一个幂等的SinkFunction,该函数将事件写入JDBC数据库。
1 | class DerbyUpsertSink extends RichSinkFunction[SensorReading] { |
8.4.2 事务性数据汇连接器
为了简化事务性数据汇的实现,Flink的DataStream API提供了两个模板,可以通过继承这些模板来实现自定义数据汇算子。两个模板都实现了CheckpointListener接口来接收JobManager发出的检查点已完成的通知
- GenericWriteAheadSink模板暂存每个检查点周期内所有需要发出到外部系统的记录,并将它们存储在数据汇算子任务的算子状态中。当任务接收到检查点完成通知时,它将已完成的那个检查点周期内的记录写入外部系统。
- TwoPhaseCommitSinkFunction模板利用了外部汇系统的事务特性。对于每个检查点,它启动一个新事务,并将这个检查点周期内的事件写入到这个事务中。
8.4.2.1 GenericWriteAheadSink(WAL)
GenericWriteAheadSink的工作方式如下:
- 它将所有接收到的记录添加(append)到使用检查点来分段(segmented)的**write ahead log(**WAL)中。
- 每次数据汇算子接收到检查点分隔符时,它将开启一个新的section,并将以下所有记录追加到新section。
- WAL作为算子状态被存储,当生成检查点时,WAL被发送给远程存储。
- 由于WAL可以在出现故障时恢复,因此不会丢失任何记录。
当GenericWriteAheadSink收到关于已完成检查点的通知时,它会将WAL中对应这个检查点的section中所有记录发送给外部系统。
当所有记录都被成功发出后,GenericWriteAheadSink将在内部提交相应的检查点。检查点需要通过两个步骤提交。
- 首先,数据汇永久存储"这个检查点已提交了"这条提交信息。
- 其次,它从WAL中删除对应的section中全部记录。
- 注意:提交信息不存储算子状态中。相反,GenericWriteAheadSink依赖于一个称为CheckpointCommitter的可插入组件来存储和查找提交信息。
下面看看如何利用GenericWriteAheadSink来实现一个事务性数据汇连接器
1 | avgTemp.transform( |
如前所述,GenericWriteAheadSink不能提供100%的精确一次一致性保证。有两种失败情况会导致记录被多次发出:
- 程序在任务运行sendValues()方法时发生故障。
- 这时,单个section中有的记录被写入了外部系统但是有的没有写入。
- 然后由于检查点尚未提交,当恢复时,数据汇将再次写入这个section中的所有记录。
- 从而导致记录多次发送。
- 所有记录都被正确写入,sendValues()方法返回true;但是,程序在调用CheckpointerCommitter之前失败,或者CheckpointerCommitter未能提交检查点。这样,在恢复期间,系统会误认为这个checkpoint未内部提交,并再次写入这个section中的所有记录。
8.4.2.1 TwoPhaseCommitSinkFunction(2PC)
TwoPhaseCommitSinkFunction是这样实现2PC协议的。
- 在数据汇向外部汇系统发出它的第一个记录之前,它在外部汇系统上启动一个事务。
- 这之后收到的所有记录都写入到这个事务中。
- 当JobManager启动一个检查点并在数据源中放入检查点分隔符时,2PC协议的投票阶段开始。
- 当一般算子接收到检查点分隔符时,它向远程存储同步自己的状态,并在完成之后向JobManager发送确认消息。
- 当数据汇算子任务接收到检查点分隔符时,它向远程存储同步自己的状态,准备好要提交事务,并在完成之后向JobManager发送确认消息。
- JobManager收到的确认消息类似于2PC协议的提交投票。数据汇任务此时还不能提交事务,因为不能保证所有其他数据汇任务都到达了检查点。此时数据汇任务会再开启一个新的事务,将到来的记录写入到这个新事务中。
- 当JobManager从所有任务上接收到确认消息时,它将检查点完成通知 发送给所有订阅通知的任务。此通知对应于2PC协议的commit命令。
- 当数据汇任务收到通知时,它提交检查点对应的事务。
- 当所有的数据汇任务都提交了它们的事务时,2PC协议的迭代就成功了。
要实现2PC协议,还需要外部汇系统满足一些要求
- 外部汇系统必须提供事务支持。
- 在检查点间隔期间,事务必须打开并接受写操作。
- 事务必须直到收到检查点完成通知才能提交。在恢复周期的情况下,这可能需要一些时间。如果接收系统关闭事务(例如因超时关闭了事务),未提交的数据将丢失。
- 外部汇系统必须能够在进程失败后恢复事务。
- 提交事务必须是幂等操作——外部汇系统应该能够注意到事务已经提交,或者重复提交必须没有效果。
下面实例将2PC作用在一个文件系统上
1 | class TransactionalFileSink(val targetPath: String, val tempPath: String) |
8.5 异步访问外部系统
除了接收(ingest)或发出(emit)数据流之外,通过在远程数据库中查找信息来丰富数据流是另一个需要与外部存储系统交互的常见场景。比如:雅虎的广告分析系统,它需要使用存储在键值存储中的对应广告的详细信息来丰富广告点击流。
对于这类场景,最直接的方法是实现一个MapFunction,它为每个记录查询外部系统,等待查询返回结果,丰富记录,并发出结果。虽然这种方法很容易实现,但存在一个主要问题:对外部系统的每个请求都会增加显著的延迟(一个请求/响应涉及两个网络消息),而MapFunction将大部分时间用于等待查询结果。
Flink提供了AsyncFunction来减轻远程I/O调用的延迟。AsyncFunction并发地发送多个查询并异步地处理它们的结果。
下面来看看AsyncFunction的源代码
1 | trait AsyncFunction[IN, OUT] extends Function { |
下面展示如何使用AsyncFunction来并发查询关系型数据库(这里使用Derby数据库)
1 | val readings: DataStream[SensorReading] = ??? |
- asyncInvoke()方法包装了阻塞式的JDBC查询
- 这些JDBC查询通过CachedThreadPool执行。
- Future[String]返回JDBC查询的结果。
- 最后,我们调用Future对象(也就是上面代码的room常量)onComplete()回调,并将查询结果传递给ResultFuture handler。
- 将查询结果传递给ResultFuture handler是由DirectExecutor处理的。
值得一提的是,asyncInvoke方法本身与其他算子函数没有区别,都是串行调用的。只不过它在内部使用了Future对象来发出并回收异步请求。