
第3章 Kafka生产者——向Kafka写入数据
对应代码仓库地址:https://github.com/T0UGH/getting-started-kafka
参考资料:
kafka权威指南https://book.douban.com/subject/27665114/
大数据通用的序列化器——Apache Avrohttps://www.jianshu.com/p/0a85bfbb9f5f
Kafka 中使用 Avro 序列化框架(一)https://www.jianshu.com/p/4f724c7c497d
Kafka 中使用 Avro 序列化组件(三):Confluent Schema Registryhttps://www.jianshu.com/p/cd6f413d35b0
本章对应代码仓库可查看https://github.com/T0UGH/getting-started-kafka/tree/main/src/main/java/cn/edu/neu/demo/ch3
在这一章,我们将从Kafka生产者的设计和组件讲起,学习如何使用Kafka 生产者。
- 我们将演示如何创建KafkaProducer和ProducerRecords对象、
- 如何将记录发送给Kafka
- 如何处理从Kafka返回的错误
- 介绍用于控制生产者行为的重要配置选项
- 深入探讨如何使用不同的分区方法和序列化器,以及如何自定义序列化器和分区器。
3.1 生产者概览
先展示向Kafka发送消息的主要步骤

-
首先创建一个ProducerRecord对象开始,ProducerRecord 对象需要包含目标主题和要发送的内容,有可能还包含键和分区信息
-
把ProducerRecord中的键和值序列化成字节数组,这样它们才能够在网络上传输
-
接下来,数据被传给分区器。
- 如果之前在ProducerRecord对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。
- 如果没有指定分区,那么分区器会根据ProducerRecord对象的键来选择一个分区。
-
紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。
-
有一个独立的线程负责把这些记录批次发送到相应的broker 上。
-
服务器在收到这些消息时会返回一个响应。
-
如果消息成功写入Kafka,就返回一个RecordMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。
-
如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
-
3.2 创建Kafka生产者
下面展示如何创建一个KafkaProducer
1 | Properties kafkaProperties = new Properties(); |
在创建Kafka生产者之前,有3个必选的配置项
| 配置项 | 解释 |
|---|---|
| bootstrap.servers | 该属性指定broker 的地址清单,地址的格式为host:port, host:port。 |
| key.serializer | key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer 接口的类,生产者会使用这个类把键序列化成字节数组。Kafka 客户端默认提供了ByteArraySerializer、StringSerializer 和IntegerSerializer |
| value.serializer | 与key.serializer 一样,value.serializer 指定的类会将值序列化。 |
3.3 发送消息到Kafka
实例化生产者对象后,接下来就可以开始发送消息了。发送消息主要有以下3 种方式:
- 发送并忘记(fire-and-forget)
- 我们把消息发送给服务器,但并不关心它是否正常到达。
- 大多数情况下,消息会正常到达,因为Kafka 是高可用的,而且生产者会自动尝试重发。
- 不过,使用这种方式有时候也会丢失一些消息。
- 同步发送
- 我们使用send() 方法发送消息,它会返回一个Future 对象,调用get() 方法进行等待,就可以知道消息是否发送成功。
- 异步发送
- 我们调用send() 方法,并指定一个回调函数,服务器在返回响应时调用该函数。
下面分别演示这三种方式
3.3.1 发送并忘记
1 | ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>( |
- 生产者的send() 方法将ProducerRecord对象作为参数。ProducerRecord中包含目标主题的名字和要发送的键对象和值对象。
- 我们使用生产者的send()方法发送ProducerRecord对象。send() 方法会返回一个包含RecordMetadata 的Future对象,不过因为我们这里忽略了返回值,所以无法知道消息是否发送成功。如果不关心发送结果,那么可以使用这种发送方式。比如,记录日志。
- 虽然我们忽略返回值的同时也忽略了返回的异常。不过在发送消息之前,生产者还是有可能发生其他的异常,这些异常将被抛出。这些异常有可能是:
- SerializationException(说明序列化消息失败)
- BufferExhaustedException 或TimeoutException(说明缓冲区已满)
- 又或者是InterruptException(说明发送线程被中断)。
3.3.2 同步发送
1 | ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>( |
-
producer.send()方法先返回一个Future对象,然后调用Future 对象的get()方法会阻塞当前线程来等待Kafka响应。
- 如果服务器返回一个错误,get() 方法会抛出异常。
- 否则,我们会得到一个RecordMetadata对象,可以通过它获取消息的主题、分区、偏移量等信息。
-
如果在发送消息之前或者在发送消息的过程中发生了任何错误,比如broker 返回了一个不允许重发消息的异常或者已经超过了重发的次数,那么就会抛出异常。
KafkaProducer一般会发生两类错误。
- 一类是可重试错误,这类错误可以通过重发消息来解决。比如对于连接错误,可以通过再次建立连接来解决,“无主(no leader)”错误则可以通过重新为分区选举首领来解决。KafkaProducer 可以被配置成自动重试,如果在多次重试后仍无法解决问题,应用程序会收到一个重试异常。
- 另一类错误无法通过重试解决,比如“消息太大”异常。对于这类错误,KafkaProducer直接抛出异常。
3.3.3 异步发送
如果只发送消息而不等待响应,那么可以避免阻塞线程来等待,从而提高发送效率。
大多数时候,我们并不需要等待响应——尽管Kafka会把目标主题、分区信息和消息的偏移量发送回来,但对于发送端的应用程序来说不是必需的。不过在遇到消息发送失败时,我们需要抛出异常、记录错误日志,或者把消息写入“错误消息”文件以便日后分析。
这时我们可以为send()方法注册一个回调函数,让它来处理异步调用的返回结果
1 | // 创建ProducerRecord,它是一种消息的数据结构 |
- 这里通过注册一个回调函数来处理异步发送的结果
- 如果错误,则
onCompletion方法的Exception参数不为null,我们可以针对这个异常进行处理 - 如果没有错误,
RecordMetadata不为null,我们可以从中获取主题信息、分区信息、偏移量信息
- 如果错误,则
3.4 生产者的配置
生产者还有很多可配置的参数,在Kafka 文档里都有说明,它们大部分都有合理的默认值,所以没有必要去修改它们。不过有几个参数在内存使用、性能和可靠性方面对生产者影响比较大,接下来我们会一一说明。
3.4.1 acks
acks参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
-
如果acks=0,生产者发送消息之后就立刻认为消息写入成功。
- 也就是说,如果服务器没有收到消息,生产者也无从得知,消息也就丢失了。
- 不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
-
如果acks=1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应。
- 如果消息无法到达首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。
-
如果acks=all,只有当首领节点和所有复制节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
- 这种模式是最安全的。
- 不过,它的延迟比acks=1 时更高,因为我们要等待不只一个服务器节点接收消息。
3.4.2 retries(重试次数)
retries 参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms。
因为生产者会自动进行重试,所以就没必要在代码逻辑里处理那些可重试的错误。你只需要处理那些不可重试的错误或重试次数超出上限的情况。
3.4.3 batch.size(批次大小)和linger.ms(批次等待时间)
KafkaProducer会在批次填满或linger.ms达到上限时把批次发送出去。
该参数指定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数)。当批次被填满,批次里的所有消息会被发送出去。
该参数指定了生产者在发送批次之前等待更多消息加入批次的时间
3.4.4 max.in.flight.requests.per.connection
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。
- 它的值越高,就会占用越多的内存,不过也会提升吞吐量。
- 把它设为1可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
3.5 序列化器
我们已经在之前的例子里看到,创建一个生产者对象必须指定序列化器。我们已经知道如何使用默认的字符串序列化器,Kafka 还提供了整型和字节数组序列化器,不过它们还不足以满足大部分场景的需求。到最后,我们需要序列化的记录类型会越来越多。
接下来演示如何开发自定义序列化器,并介绍Avro序列化器。如果发送到Kafka的对象 不是简单的字符串或整型,那么可以使用序列化框架来创建消息记录,如Avro、Thrift 或Protobuf,或者使用自定义序列化器。我们强烈建议使用通用的序列化框架。
3.5.1 自定义序列化器
1 | /** |
1 | /** |
不过我们不建议采用自定义序列化器,理由如下
- 如果我们有多种类型的消费者,可能需要把customerID 字段变成长整型,或者为Customer 添加startDate 字段,这样就会出现新旧消息的兼容性问题。
- 在不同版本的序列化器和反序列化器之间调试兼容性问题着实是个挑战——你需要比较原始的字节数组。
- 更糟糕的是,如果同一个公司的不同团队都需要往Kafka 写入Customer 数据,那么他们就需要使用相同的序列化器,如果序列化器发生改动,他们几乎都要在同一时间修改代码。
3.5.2 使用Avro序列化
Apache Avro是一种与编程语言无关的序列化格式。
Avro数据通过与语言无关的schema来定义。
- schema通过JSON来描述,
- 数据可以被序列化成二进制文件或JSON 文件,不过一般会使用二进制文件。
- Avro 在读写文件时需要用到schema,schema 一般会被内嵌在数据文件里。
Avro 有一个很有意思的特性是,当负责写消息的应用程序使用了新版本的schema,负责读消息的应用程序可以继续处理消息而无需做任何改动,这个特性使得它特别适合用在像Kafka 这样的消息系统上。
下面举个例子
假设我们有一个v0.0.1的schema
2
3
4
5
6
7
8
9
10
11
> "namespace": "customerManagement.avro",
> "type": "record",
> "name": "Customer",
> "fields": [
> {"name": "id", "type": "int"},
> {"name": "name", "type": "string"},
> {"name": "faxNumber", "type": ["null", "string"], "default": "null"}
> ]
> }
>
过了一段时间,我们需要删除
faxnumber字段(传真号码),添加一个
2
3
4
5
6
7
8
9
10
11
> "namespace": "customerManagement.avro",
> "type": "record",
> "name": "Customer",
> "fields": [
> {"name": "id", "type": "int"},
> {"name": "name", "type": "string"},
> {"name": "email", "type": ["null", "string"], "default": "null"}
> ]
> }
>
更新到新版的schema 后:
- 旧记录仍然包含faxNumber 字段
- 而新记录则包含email 字段
- 部分负责读取数据的应用程序进行了升级,那么它们是如何处理这些变化的呢?
在消费者升级之前:
- 它们会调用类似getName()、getId() 和getFaxNumber() 这样的方法。
- 如果碰到使用新schema 构建的消息,getName() 和getId() 方法仍然能够正常返回,但getFaxNumber() 方法会返回null,因为消息里不包含传真号码。
在消费者升级之后
- getEmail() 方法取代了getFaxNumber() 方法。
- 如果碰到一个使用旧schema 构建的消息,那么getEmail() 方法会返回null,因为旧消息不包含邮件地址。
现在可以看出使用Avro 的好处了:我们修改了消息的schema,但并不需要更新所有消费者,而这样仍然不会出现异常或阻断性错误,也不需要对现有数据进行大幅更新。
3.5.3 在Kafka中使用Avro
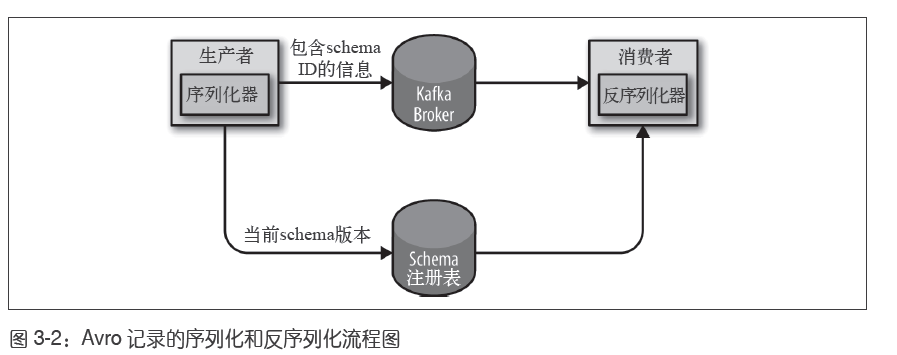
如果在每条Kafka 记录里都嵌入schema,会让记录的大小成倍地增加。
- 但是在读取记录时仍然需要用到整个schema,所以要先找到schema。
- 我们要使用“schema 注册表”来达到目的。
- Kafka中并不包含schema注册表的实现,现在已经有一些开源的schema注册表实现,比如:Confluent Schema Registry。
- 我们把所有写入数据需要用到的schema保存在注册表里,然后在记录里放一个schema的标识符。
- 消费者使用记录中的标识符从注册表里拉取schema来反序列化记录。
3.6 分区
在之前的例子里,ProducerRecord对象包含了目标主题、键和值。Kafka 的消息是一个个键值对,ProducerRecord 对象可以只包含目标主题和值,键可以设置为默认的null,不过大多数应用程序会用到键。
键有两个用途:
- 可以作为消息的附加信息,
- 也可以用来决定消息该被写到主题的哪个分区。拥有相同键的消息将被写到同一个分区。
如果要创建键为null的消息,不指定键就可以
1 | ProducerRecord<Integer, String> record = new ProducerRecord<>("CustomerCountry", "USA"); |
如果键为null,并且使用了默认的分区器,那么记录将被随机地发送到主题内各个可用的分区上。分区器使用轮询(Round Robin)算法将消息均衡地分布到各个分区上。
如果键不为空,并且使用了默认的分区器,那么Kafka会使用Kafka自己的散列算法对键进行散列(使用Kafka 自己的散列算法,即使升级Java 版本,散列值也不会发生变化),然后根据散列值把消息映射到特定的分区上。这里的关键之处在于,同一个键总是被映射到同一个分区上。
只有在不改变主题分区数量的情况下,键与分区之间的映射才能保持不变。举个例子,在分区数量保持不变的情况下,可以保证用户045189 的记录总是被写到分区34。在从分区读取数据时,可以进行各种优化。不过,一旦主题增加了新的分区,这些就无法保证了——旧数据仍然留在分区34,但新的记录可能被写到其他分区上。如果要使用键来映射分区,那么最好在创建主题的时候就把分区规划好,而且永远不要增加新分区。
3.6.1 自定义分区器
默认情况下,kafka自动创建的主题的分区数量为1,所以我们需要先修改分区数量,来让自定义分区器有点用。
-
先cd到
opt\kafka\bin\ -
运行命令:
1
./kafka-topics.sh --zookeeper 47.94.139.116:2181/kafka --alter --topic sun --partitions 4
-
查看是否修改成功
1
./kafka-topics.sh --describe --zookeeper 47.94.139.116:2181/kafka --topic sun

或者也可以通过修改server.properties中的nums.partions并重启,来更改默认分区数量。
下面自定义一个分区器,它根据键来划分分区:若键为Banana则放入最后一个分区,若键不为Banana则散列到其他分区。
1 | /** |
然后,在producer配置中加入kafkaProperties.put("partitioner.class", "cn.edu.neu.demo.ch3.partitioner.BananaPartitioner");即可。