
第2章 机器学习概述
机器学习是对能通过经验自动改进的计算机算法的研究.——汤姆·米切尔(Tom Mitchell)
机器学习(Machine Learning,ML)就是让计算机从数据中进行自动学习,得到某种知识(或规律).即如何从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据进行预测.
机器学习任务的特点是,对于我们人类而言,这些任务很容易完成,但我们不知道自己是如何做到的,因此也很难人工设计一个计算机程序来完成这些任务.一个可行的方法是设计一个算法可以让计算机自己从有标注的样本上学习其中的规律,并用来完成各种识别任务.
以手写数字识别为例子:要识别手写体数字,首先通过人工标注大量的手写体数字图像(即每张图像都通过人工标记了它是什么数字),这些图像作为训练数据,然后通过学习算法自动生成一套模型,并依靠它来识别新的手写体数字.这个过程和人类学习过程也比较类似,我们教小孩子识别数字也是这样的过程.这种通过数据来学习的方法就称为机器学习的方法.
2.1 基本概念
首先我们以一个生活中的例子来介绍机器学习中的一些基本概念:样本、特征、标签、模型、学习算法等.
首先,我们从市场上随机选取一些芒果,列出每个芒果的特征(Feature),包括颜色、大小、形状、产地、品牌,以及我们需要预测的标签(Label).标签可以是连续值(比如关于芒果的甜度、水分以及成熟度的综合打分),也可以是离散值(比如“好”“坏”两类标签)
我们可以将一个标记好特征以及标签的芒果看作一个样本(Sample)一组样本构成的集合称为数据集(Data Set). 一般将数据集分为两部分:训练集和测试集.训练集(Training Set)中的样本是用来训练模型的,也叫训练样本(Training Sample),而测试集(Test Set)中的样本是用来检验模型好坏的,也叫测试样本(Test Sample).
我们通常用一个维向量 表示一个芒果的所有特征构成的向量,称为特征向量(Feature Vector),其中每一维表示一个特征.而芒果的标签通常用标量来表示.
假设训练集由个样本组成,其中每个样本都是独立同分布的(Identically and Independently Distributed,IID),即独立地从相同的数据分布中抽取的,记为
给定训练集𝒟,我们希望让计算机从一个函数集合 中自动寻找一个“最优”的函数 来近似每个样本的特征向量和标签之间的真实映射关系.对于一个样本,我们可以通过函数 来预测其标签的值
如何寻找这个“最优”的函数 是机器学习的关键,一般需要通过学习算法(Learning Algorithm)来完成.这个寻找过程通常称为学习(Learning)或训练(Training)过程.
为了评价的公正性,我们还是独立同分布地抽取一组芒果作为测试集,并在测试集中所有芒果上进行测试,计算预测结果的准确率
其中为指示函数,为测试集的大小
图2.2给出了机器学习的基本流程.对一个预测任务,输入特征向量为,输出标签为,我们选择一个函数集合,通过学习算法和一组训练样本,从中学习到函数.这样对新的输入,就可以用函数 $ f^∗(𝒙)$进行预测.
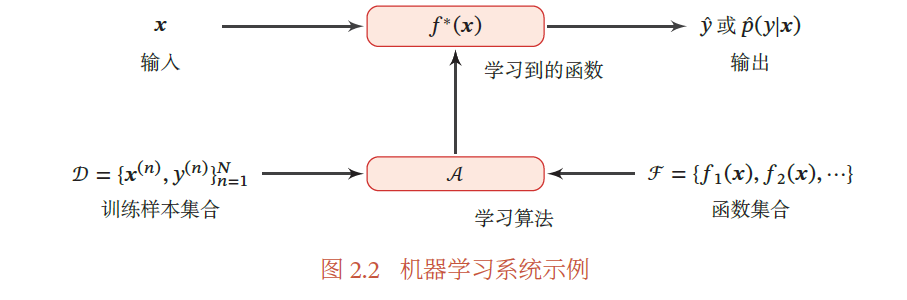
2.2 机器学习的三个基本要素
机器学习方法可以粗略地分为三个基本要素:模型、学习准则、优化算法.
2.2.1 模型
对于一个机器学习任务,首先要确定其输入空间 和输出空间.不同机器学习任务的主要区别在于输出空间不同.在二分类问题中,在𝐶 分类问题中,而在回归问题中.
输入空间和输出空间构成了一个样本空间.对于样本空间中的样本,假定𝒙 和𝑦 之间的关系可以通过一个未知的真实映射函数 或真实条件概率分布来描述.机器学习的目标是找到一个模型来近似真实映射函数 或真实条件概率分布.
通常根据经验来假设一个函数集合,称为假设空间(Hypothesis Space),然后通过观测其在训练集上的特性,从中选择一个理想的假设(Hypothesis).
假设空间通常为一个参数化的函数族
其中f(𝒙;𝜃) 是参数为𝜃的函数,也称为模型(Model),为参数的数量.
2.2.1.1 线性模型
线性模型的假设空间为一个参数化的线性函数族,即
𝑓(𝒙; 𝜃) = 𝒘^T𝒙 + 𝑏
其中参数𝜃包含了权重向量和偏置.
2.2.1.2 非线性模型
广义的非线性模型可以写为多个非线性基函数𝜙(𝒙) 的线性组合
f(𝒙;𝜃) = 𝒘^T𝜙(𝒙) + 𝑏
其中𝜙(𝒙) = [𝜙_1(𝒙), 𝜙_2(𝒙), ⋯ , 𝜙_𝐾 (𝒙)]^T为𝐾 个非线性基函数组成的向量,参数𝜃
包含了权重向量𝒘 和偏置𝑏.
2.2.2 学习准则
一个好的模型f(𝒙, 𝜃^∗)应该在所有 的可能取值上都与真实映射函数一致,即
|𝑓(𝒙, 𝜃^∗) − 𝑦| < 𝜖, ∀(𝒙, 𝑦) ∈ X × Y
或与真实条件概率分布一致,即
|f_y(𝒙, 𝜃^∗) − 𝑝_𝑟(𝑦|𝒙)| < 𝜖, ∀(𝒙, 𝑦) ∈ X × Y,
其中**𝜖是一个很小的正数**,𝑓_𝑦(𝒙, 𝜃∗)为模型预测的条件概率分布中对应的概率.
模型f(𝒙; 𝜃) 的好坏可以通过期望风险(Expected Risk)R(𝜃) 来衡量,其定义为
R(𝜃) = 𝔼_{(𝒙,𝑦)∼𝑝𝑟(𝒙,𝑦)}[L(𝑦, 𝑓(𝒙; 𝜃))],
其中 为真实的数据分布,L(𝑦, 𝑓(𝒙; 𝜃))为损失函数,用来量化两个变量之间的差异.(y为真实值,f(x,𝜃)为预测值)
2.2.2.1 损失函数
损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异.下面介绍几种常用的损失函数.
0-1损失函数
最直观的损失函数是模型在训练集上的错误率,即0-1 损失函数(0-1 Loss Function)
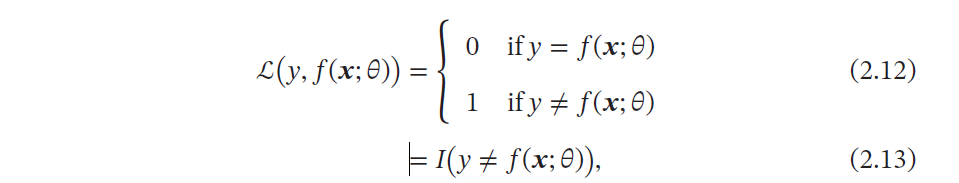
虽然0-1损失函数能够客观评价模型的好坏,但其缺点是数学性质不够好;不连续且导数为0,难以优化
平方损失函数
平方损失函数(Quadratic Loss Function)经常用在预测标签𝑦为实数值的任务中,定义为
L(𝑦, 𝑓(𝒙; 𝜃)) =\frac{1}{2}(𝑦 − 𝑓(𝒙; 𝜃))^2
但一般不适合分类问题
交叉熵损失函数
交叉熵损失函数(Cross-Entropy Loss Function)一般用于分类问题.假设样本的标签 为离散的类别,模型f(𝒙; 𝜃) ∈ [0, 1]^𝐶的输出为类别标签的条件概率分布,即
p(y=c|x;𝜃) = f_c(x;𝜃)
并满足
f_c(x;𝜃) ∈ [0, 1], \sum^{C}_{c=1}f_c(x;𝜃)=1
我们可以用一个𝐶 维的one-hot 向量 来表示样本标签.假设样本的标签为,那么标签向量 只有第维的值为1,其余元素的值都为0.标签向量可以看作样本标签的真实条件概率分布,即第维(记为,)是类别为 的真实条件概率.假设样本的类别为,那么它属于第类的概率为1,属于其他类的概率为0.
对于两个概率分布,一般可以用交叉熵来衡量它们的差异.标签的真实分布和模型预测分布f(𝒙; 𝜃)之间的交叉熵为
L(𝒚, 𝑓(𝒙; 𝜃)) = −𝒚^Tlogf(𝒙; 𝜃) = −\sum^C_{c=1}y_c log𝑓_𝑐(𝒙; 𝜃).
比如对于三分类问题,一个样本的标签向量为,模型预测的标签分布为𝑓(𝒙; 𝜃) = [0.3, 0.3, 0.4]^T,则它们的交叉熵为.
Hinge损失函数
略
2.2.2.2 风险最小化准则
一个好的模型𝑓(𝒙; 𝜃) 应当有一个比较小的期望错误,但由于不知道真实的数据分布和映射函数,实际上无法计算其期望风险ℛ(𝜃)
给定一个训练集,我们可以计算的是经验风险(Empirical Risk),即在训练集上
的平均损失:
R^{emp}_D(𝜃) = \frac{1}{N}\sum^{N}_{n=1}L(𝑦(𝑛), 𝑓(𝒙(𝑛); 𝜃))
一个切实可行的学习准则是找到一组参数𝜃^∗ 使得经验风险最小,即
𝜃^∗ = arg_𝜃minR^{emp}_D(𝜃)
这就是**经验风险最小化(Empirical Risk Minimization, ERM)**准则
根据大数定理可知,当训练集大小 趋向于无穷大时,经验风险就趋向于期望风险. 然而通常情况下,我们无法获取无限的训练样本,并且训练样本往往是真实数据的一个很小的子集或者包含一定的噪声数据,不能很好地反映全部数据的真实分布.经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高.这就是所谓的过拟合(Overfitting).
定义2.1 – 过拟合: 给定一个假设空间ℱ,一个假设𝑓 属于ℱ,如果存在其他的假设𝑓′ 也属于ℱ, 使得在训练集上𝑓 的损失比𝑓′ 的损失小,但在整个样本空间上𝑓′ 的损失比𝑓 的损失小,那么就说假设𝑓 过度拟合训练数据
过拟合问题往往是由于训练数据少和噪声以及模型能力强等原因造成的.为了解决过拟合问题, 一般在经验风险最小化的基础上再引入参数的正则化(Regularization)来限制模型能力,这就是**结构风险最小化(Structure Risk Minimization,SRM)**准则:
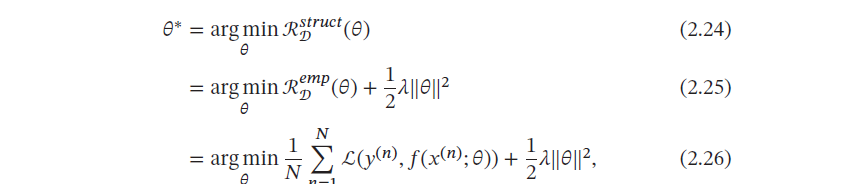
其中‖𝜃‖ 是ℓ2 范数的正则化项,用来减少参数空间,避免过拟合;𝜆 用来控制正则化的强度.
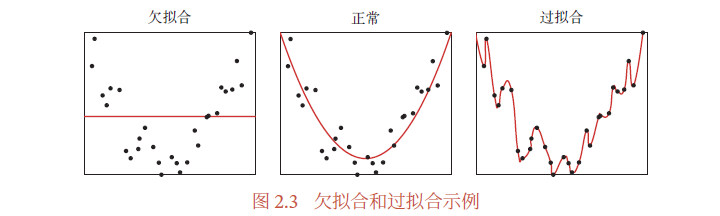
和过拟合相反的一个概念是欠拟合(Underfitting),即模型不能很好地拟合训练数据,在训练集上的错误率比较高.欠拟合一般是由于模型能力不足造成的.图2.3给出了欠拟合和过拟合的示例.
总之,机器学习中的学习准则并不仅仅是拟合训练集上的数据,同时也要使得泛化错误最低.给定一个训练集,机器学习的目标是从假设空间中找到一个泛化错误较低的“理想”模型,以便更好地对未知的样本进行预测,特别是不在训练集中出现的样本.因此,我们可以将机器学习看作一个从有限、高维、有噪声的数据上得到更一般性规律的泛化问题.
2.2.3 优化算法
如何找到最优的模型f(𝒙, 𝜃^∗) 就成了一个**最优化(Optimization)**问题.机器学习的训练过程其实就是最优化问题的求解过程.
在机器学习中,优化又可以分为参数优化和超参数优化.模型f(𝒙; 𝜃) 中的𝜃称为模型的参数,可以通过优化算法进行学习.除了可学习的参数𝜃之外,还有一类参数是用来定义模型结构或优化策略的,这类参数叫作超参数(Hyper-Parameter).
常见的超参数包括:聚类算法中的类别个数、梯度下降法中的步长、正则化项的系数、神经网络的层数、支持向量机中的核函数等.
超参数的选取一般都是组合优化问题,很难通过优化算法来自动学习.因此,超参数优化是机器学习的一个经验性很强的技术,通常是按照人的经验设定,或者通过搜索的方法对一组超参数组合进行不断试错调整.
2.2.3.1 梯度下降法
在机器学习中,最简单、常用的优化算法就是梯度下降法,即首先初始化参数𝜃_0,然后按下面的迭代公式来计算训练集𝒟 上风险函数的最小值:
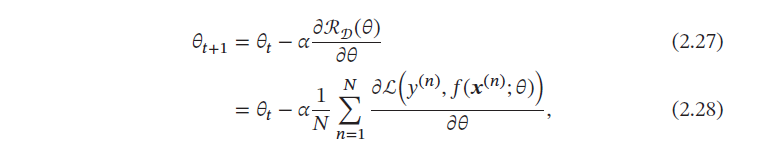
其中𝜃_𝑡 为第𝑡 次迭代时的参数值,𝛼 为搜索步长.在机器学习中,𝛼 一般称为学习率(Learning Rate).
2.2.3.2 提前停止
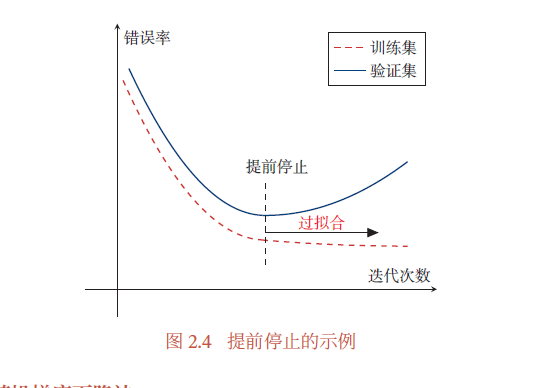
针对梯度下降的优化算法,除了加正则化项之外,还可以通过提前停止来防止过拟合.
在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数,并不一定在测试集上最优.因此,除了训练集和测试集之外,有时也会使用一个验证集(Validation Set).在每次迭代时,把新得到的模型𝑓(𝒙; 𝜃)在验证集上进行测试,并计算错误率.(Development Set).如果在验证集上的错误率不再下降,就停止迭代.这种策略叫提前停止(Early Stop)
2.2.3.3 随机梯度下降法
目标函数是整个训练集上的风险函数,这种方式称为批量梯度下降法(Batch Gradient Descent,BGD).批量梯度下降法在每次迭代时需要计算每个样本上损失函数的梯度并求和.当训练集中的样本数量𝑁 很大时,空间复杂度比较高,每次迭代的计算开销也很大.
为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法(Stochastic Gradient Descent,SGD).当经过足够次数的迭代时,随机梯度下降也可以收敛到局部最优解.

随机梯度下降相当于在批量梯度下降的梯度上引入了随机噪声.在非凸优化问题中,随机梯度下降更容易逃离局
部最优点.
2.2.3.4 小批量梯度下降法
随机梯度下降法的一个缺点是无法充分利用计算机的并行计算能力.小批量梯度下降法(Mini-Batch Gradient Descent)是批量梯度下降和随机梯度下降的折中.每次迭代时,我们随机选取一小部分训练样本来计算梯度并更新参数,这样既可以兼顾随机梯度下降法的优点,也可以提高训练效率.
小批量随机梯度下降法有收敛快、计算开销小的优点,因此逐渐成为大规模的机器学习中的主要优化算法
2.3 机器学习的简单示例——线性回归
线性回归(Linear Regression)是一种对自变量和因变量之间关系进行建模的回归分析.自变量数量为1 时称为简单回归,自变量数量大于1 时称为多元回归.
从机器学习的角度来看,自变量就是样本的特征向量(每一维对应一个自变量),因变量是标签𝑦,这里𝑦 ∈ ℝ 是连续值(实数或连续整数).假设空间是一组参数化的线性函数
为简单起见,我们将公式(2.30) 写为
和分别称为增广权重向量和增广特征向量
2.3.1 参数学习
给定一组包含𝑁 个训练样本的训练集𝒟,我们希望能够学习一个最优的线性回归的模型参数𝒘.
我们介绍四种不同的参数估计方法:经验风险最小化、结构风险最小化、最大似然估计、最大后验估计.
2.3.1.1 经验风险最小化
由于线性回归的标签𝑦和模型输出都为连续的实数值, 因此平方损失函数非常适合衡量真实标签和预测标签之间的差异.
根据经验风险最小化准则,训练集𝒟 上的经验风险定义为每个样本损失函数的和

其中 是由所有样本的真实标签组成的列向量,而 是由所有样本的输入特征 组成的矩阵:
风险函数 是关于𝒘 的凸函数(二阶导数小于0),其对𝒘的偏导数为

在最小二乘法中, 必须存在逆矩阵,即 是满秩的
一种常见的 不可逆情况是样本数量𝑁 小于特征数量(𝐷 + 1),的秩为𝑁.这时会存在很多解𝒘∗,可以使得ℛ(𝒘∗) = 0.
当 不可逆时,可以通过下面两种方法来估计参数:
- 先使用主成分分析等方法来预处理数据,消除不同特征之间的相关性,然后再使用最小二乘法来
估计参数; - 使用梯度下降法来估计参数.先初始化𝒘 = 0,然后进行迭代.利用梯度下降法来求解的方法也称为最小均方(Least
**Mean Squares,LMS)**算法
2.3.1.2 结构风险最小化
即使 可逆,如果特征之间有较大的多重共线性(Multicollinearity,共线性是指一个特征可以通过其他特征的线性组合来较准确地预测.),也会使得 的逆在数值上无法准确计算.数据集𝑿 上一些小的扰动就会导致发生大的改变,进而使得最小二乘法的计算变得很不稳定.岭回归(Ridge Regression)解决这个问题,给的对角线元素都加上一个常数𝜆 使得(𝑿𝑿T + 𝜆𝐼) 满秩,即其行列式不为0.其中𝜆 > 0 为预先设置的超参数,𝐼 为单位矩阵.最优的参数𝒘∗ 为
𝒘∗ = (𝑿𝑿^T + 𝜆𝐼)^{−1}𝑿𝒚
岭回归的解𝒘∗ 可以看作结构风险最小化准则下的最小二乘法估计,其目标函数(经验风险)可以写为
R(𝒘) = \frac12 ‖𝒚 − 𝑿^T𝒘‖^2 + \frac12𝜆‖𝒘‖2
2.3.1.3 最大似然估计
机器学习任务可以分为两类: 一类是样本的特征向量𝒙 和标签𝑦 之间存在未知的函数关系𝑦 = ℎ(𝒙),另一类是条件概率𝑝(𝑦|𝒙) 服从某个未知分布.
假设标签𝑦 为一个随机变量,并由函数$f(𝒙; 𝒘) = 𝒘^T𝒙 $加上一个随机噪声𝜖决定,即
𝑦 = 𝑓(𝒙; 𝒘) + 𝜖 = 𝒘^T𝒙 + 𝜖
其中𝜖服从均值为0、方差为𝜎^2 的高斯分布.这样,𝑦 服从均值为、方差为𝜎^2的高斯分布:

参数𝒘 在训练集𝒟 上的似然函数(Likelihood)为

其中为所有样本标签组成的向量,为所有样本特征向量组成的矩阵.
似然函数是关于统计模型的参数的函数.似然𝑝(𝑥|𝑤) 和概率𝑝(𝑥|𝑤) 之间的区别在于:概率𝑝(𝑥|𝑤) 是描述固定参数𝑤 时随机
变量𝑥 的分布情况,而似然𝑝(𝑥|𝑤) 则是描述已知随机变量𝑥 时不同的参数𝑤 对其分布的影响.
最大似然估计(Maximum Likelihood Estimation,MLE)是指找到一组参数𝒘 使得似然函数𝑝(𝒚|𝑿; 𝒘, 𝜎) 最大,等价于对数似然函数log 𝑝(𝒚|𝑿; 𝒘, 𝜎)最大.可得
最大似然估计的解和最小二乘法的解相同.
2.3.1.4 最大后验估计
最大似然估计的一个缺点是当训练数据比较少时会发生过拟合,估计的参数可能不准确.为了避免过拟合,我们可以给参数加上一些先验知识.
假设参数𝒘 为一个随机向量,并服从一个先验分布𝑝(𝒘; 𝜈).为简单起见,一般令𝑝(𝒘; 𝜈) 为各向同性的高斯分布:
根据贝叶斯公式,参数𝒘 的后验分布(Posterior Distribution)为
𝑝(𝒘|𝑿, 𝒚; 𝜈, 𝜎) = \frac{𝑝(𝒘, 𝒚|𝑿; 𝜈, 𝜎)}{Σ_𝒘 𝑝(𝒘, 𝒚|𝑿; 𝜈, 𝜎)} ∝ 𝑝(𝒚|𝑿, 𝒘; 𝜎)𝑝(𝒘; 𝜈),
最大似然估计和贝叶斯估计可以分别看作频率学派和贝叶斯学派对需要估计的参数𝒘 的不同解释.当𝜈 → ∞ 时,先验分布𝑝(𝒘; 𝜈) 退化为均匀分布,称为无信息先验(Non-Informative Prior),最大后验估计退化为最大似然估计.
2.4 偏差-方差分解
我们经常会在模型的拟合能力和复杂度之间进行权衡.拟合能力强的模型一般复杂度会比较高,容易导致过拟合.相反,如果限制模型的复杂度,降低其拟合能力,又可能会导致欠拟合.因此,如何在模型的拟合能力和复杂度之间取得一个较好的平衡,对一个机器学习算法来讲十分重要.偏差-方差分解(Bias-Variance Decomposition)为我们提供了一个很好的分析和指导工具.
以回归问题为例,假设样本的真实分布为,并采用平方损失函数,模型𝑓(𝒙) 的期望错误为
这个公式的意思就是当满足真实分布时,模型的期望错误
假设 为使用平方损失作为优化目标的最优模型,其损失为
𝜖 = 𝔼_{(x,y)∼𝑝_𝑟(x,y)}[(y − f^∗(x))^2].
损失𝜖 通常是由于样本分布以及噪声引起的,无法通过优化模型来减少.
那么一般模型的期望错误可以分解为
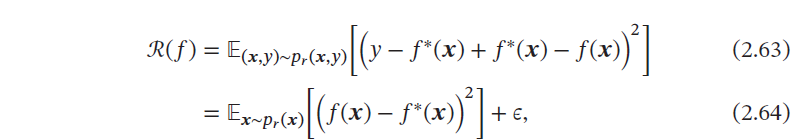
其中第一项是当前模型和最优模型之间的差距,是机器学习算法可以优化的真实目标.第二项无法优化
在实际训练一个模型𝑓(𝒙) 时,训练集𝒟 是从真实分布 上独立同分布地采样出来的有限样本集合.不同的训练集会得到不同的模型.令 表示在训练集𝒟 上学习到的模型,一个机器学习算法(包括模型以及优化算法)的能力可以用不同训练集上的模型的平均性能来评价.
对于单个样本𝒙,不同训练集𝒟 得到模型 和最优模型 的期望差距为
也就是把期望差距拆分成两部分,一部分是偏差,是指一个模型在不同训练集上的平均性能和最优模型的差异,可以用来衡量一个模型的拟合能力.第二项是方差(Variance),是指一个模型在不同训练集上的差异,可以用来衡量一个模型是否容易过拟合.

最小化期望错误等价于最小化偏差和方差之和.
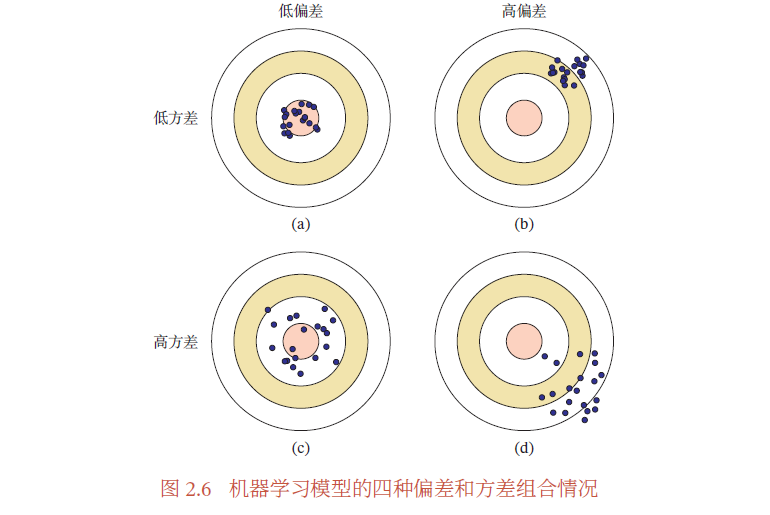
图2.6给出了机器学习模型的四种偏差和方差组合情况.每个图的中心点为最优模型𝑓∗(𝒙),蓝点为不同训练集𝐷 上得到的模型𝑓𝒟 (𝒙).图2.6a给出了一种理想情况,方差和偏差都比较低.图2.6b为高偏差低方差的情况,表示模型的泛化能力很好,但拟合能力不足.图2.6c为低偏差高方差的情况,表示模型的拟合能力很好,但泛化能力比较差.当训练数据比较少时会导致过拟合.图2.6d为高偏差高方差的情况,是一种最差的情况.
方差一般会随着训练样本的增加而减少.当样本比较多时,方差比较少,这时可以选择能力强的模型来减少偏差.
随着模型复杂度的增加,模型的拟合能力变强,偏差减少而方差增大,从而导致过拟合.以结构风险最小化为例,我们可以调整正则化系数𝜆 来控制模型的复杂度. 当𝜆 变大时,模型复杂度会降低,可以有效地减少方差,避免过拟合,但偏差会上升.
图2.7给出了机器学习模型的期望错误、偏差和方差随复杂度的变化情况,其中红色虚线表示最优模型.最优模型并不一定是偏差曲线和方差曲线的交点.
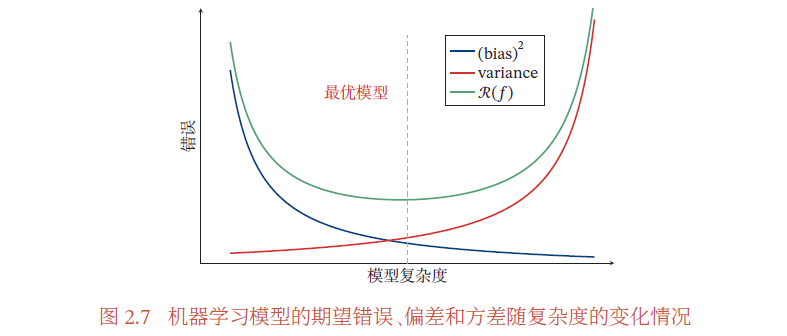
一般来说,当一个模型在训练集上的错误率比较高时,说明模型的拟合能力不够,偏差比较高.这种情况可以通过增加数据特征、提高模型复杂度、减小正则化系数等操作来改进.当模型在训练集上的错误率比较低,但验证集上的错误率比较高时,说明模型过拟合,方差比较高.这种情况可以通过降低模型复杂度、加大正则化系数、引入先验等方法来缓解.此外,还有一种有效降低方差的方法为集成模型,即通过多个高方差模型的平均来降低方差.
2.5 机器学习算法的类型
我们会按照训练样本提供的信息以及反馈方式的不同,将机器学习算法分为以下几类:
2.5.1 监督学习
如果机器学习的目标是建模样本的特征𝒙 和标签𝑦 之间的关系:𝑦 =𝑓(𝒙; 𝜃) 或𝑝(𝑦|𝒙; 𝜃),并且训练集中每个样本都有标签,那么这类机器学习称为监督学习(Supervised Learning).根据标签类型的不同,监督学习又可以分为回归问题、分类问题和结构化学习问题.
- 回归(Regression)问题中的标签𝑦 是连续值(实数或连续整数),𝑓(𝒙; 𝜃) 的输出也是连续值.
- 分类(Classification)问题中的标签𝑦 是离散的类别(符号).在分类问题中,学习到的模型也称为分类器(Classifier).分类问题根据其类别数量又可分为二分类(Binary Classification)和多分类(Multi-class Classification)问题.
- 结构化学习(Structured Learning)问题是一种特殊的分类问题.在结构化学习中,标签𝒚 通常是结构化的对象,比如序列、树或图等.由于结构化学习的输出空间比较大,因此我们一般定义一个联合特征空间,将𝒙, 𝒚 映射为该空间中的联合特征向量𝜙(𝒙, 𝒚),预测模型可以写为
𝒚 = argmax_{𝒚∈Gen(𝒙)}𝑓(𝜙(𝒙, 𝒚); 𝜃)
其中Gen(𝒙) 表示输入𝒙 的所有可能的输出目标集合.计算argmax 的过程也称为解码(Decoding)过程,一般通过动态规划的方法来计算.
2.5.2 无监督学习
无监督学习(Unsupervised Learning,UL)是指从不包含目标标签的训练样本中自动学习到一些有价值的信息.典型的无监督学习问题有聚类、密度估计、特征学习、降维等.
2.5.3 强化学习
强化学习(Reinforcement Learning,RL)是一类通过交互来学习的机器学习算法.在强化学习中,智能体根据环境的状态做出一个动作,并得到即时或延时的奖励.智能体在和环境的交互中不断学习并调整策略,以取得最大化的期望总回报.

2.6 数据的特征表示
在实际应用中,数据的类型多种多样,比如文本、音频、图像、视频等.不同类型的数据,其原始特征(Raw Feature)的空间也不相同.因此在机器学习之前我们需要将这些不同类型的数据转换为向量表示.
2.6.1 图像特征
略
2.6.2 文本特征
在文本情感分类任务中,样本𝑥 为自然语言文本,类别分别表示正面或负面的评价.为了将样本𝑥 从文本形式转为向量形式,一种简单的方式是使用词袋(Bag-of-Words,BoW)模型. 词袋模型在信息检索中也叫作向量空间模型(Vector Space Model,VSM).假设训练集合中的词都来自一个词表𝒱,大小为|𝒱|,则每个样本可以表示为一个|𝒱| 维的向量𝒙 ∈ ℝ|𝒱|.向量𝒙 中第𝑖 维的值表示词表中的第𝑖 个词是否在𝑥 中出现.如果出现,值为1,否则为0.
比如两个文本“我喜欢读书”和“我讨厌读书”中共有“我”“喜欢”“讨厌”“读书”四个词,它们的BoW 表示分别为
词袋模型将文本看作词的集合,不考虑词序信息,不能精确地表示文本信息.一种改进方式是使用N 元特征(N-Gram Feature),即每𝑁 个连续词构成一个基本单元,然后再用词袋模型进行表示.
以最简单的二元特征(即两个词的组合特征)为例,上面的两个文本中共有“$ 我”“我喜欢”“我讨厌”“喜欢读书”“讨
厌读书”“读书#”六个特征单元,它们的二元特征BoW 表示分别为
2.6.3表示学习
如果直接用数据的原始特征来进行预测,对机器学习模型的能力要求比较高.这些原始特征可能存在以下几种不足:
- 特征比较单一,需要进行(非线性的)组合才能发挥其作用;
- 特征之间冗余度比较高;
- 并不是所有的特征都对预测有用;
- 很多特征通常是易变的;
- 特征中往往存在一些噪声.
为了提高机器学习算法的能力,我们需要抽取有效、稳定的特征.传统的特征提取是通过人工方式进行的,需要大量的人工和专家知识.一个成功的机器学习系统通常需要尝试大量的特征,称为特征工程(Feature Engineering). 因此,如何让机器自动地学习出有效的特征也成为机器学习中的一项重要研究内容,称为特征学习(Feature Learning),也叫表示学习(Representation Learning).
特征学习在一定程度上也可以减少模型复杂性、缩短训练时间、提高模型泛化能力、避免过拟合等.
2.6.4 传统的特征学习
传统的特征学习一般是通过人为地设计一些准则,然后根据这些准则来选取有效的特征,具体又可以分为两种:特征选择和特征抽取.
2.6.4.1 特征选择
特征选择(Feature Selection)是选取原始特征集合的一个有效子集,使得基于这个特征子集训练出来的模型准确率最高.简单地说,特征选择就是保留有用特征,移除冗余或无关的特征.
2.6.4.2 特征抽取
特征抽取(Feature Extraction)是构造一个新的特征空间,并将原始特征投影在新的空间中得到新的表示.
特征抽取又可以分为监督和无监督的方法.监督的特征学习的目标是抽取对一个特定的预测任务最有用的特征,比如线性判别分析(Linear Discriminant Analysis,LDA).而无监督的特征学习和具体任务无关,其目标通常是减少冗余信息和噪声,比如主成分分析(Principal Component Analysis,PCA)和自编码器(Auto-Encoder,AE)
特征选择和特征抽取的优点是可以用较少的特征来表示原始特征中的大部分相关信息,去掉噪声信息,并进而提高计算效率和减小维度灾难(Curse of Dimensionality)经过特征选择或特征抽取后,特征的数量一般会减少,因此特征选择和特征抽取,也经常称为维数约减或降维(Dimension Reduction).
2.6.5 深度学习方法
传统的特征抽取一般是和预测模型的学习分离的.我们会先通过主成分分析或线性判别分析等方法抽取出有效的特征,然后再基于这些特征来训练一个具体的机器学习模型.
如果我们将特征的表示学习和机器学习的预测学习有机地统一到一个模型中,建立一个端到端的学习算法,就可以有效地避免它们之间准则的不一致性.这种表示学习方法称为深度学习(Deep Learning,DL)
2.7 评判标准
为了衡量一个机器学习模型的好坏,需要给定一个测试集,用模型对测试集中的每一个样本进行预测,并根据预测结果计算评价分数.
对于分类问题,常见的评价标准有准确率、精确率、召回率和F 值等.
给定测试集𝒯 = {(𝒙(1), 𝑦(1)), ⋯ , (𝒙(𝑁), 𝑦(𝑁))},假设标签𝑦(𝑛) ∈ {1, ⋯ , 𝐶},用学习好的模型𝑓(𝒙; 𝜃∗)对测试集中的每一个样本进行预测,结果为{𝑦(̂ 1),⋯, 𝑦(̂ 𝑁)}.
2.7.1 准确率
最常用的评价指标为准确率(Accuracy)
2.7.2 错误率
和准确率相对应的就是错误率(Error Rate):
2.7.3 精确率和召回率
准确率是所有类别整体性能的平均,如果希望对每个类都进行性能估计,就需要计算精确率(Precision)和召回率(Recall)
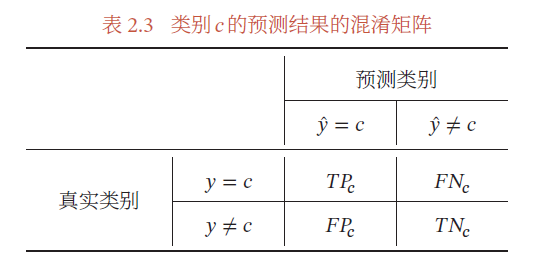
对于类别𝑐 来说,模型在测试集上的结果可以分为以下四种情况:
- 真正例(True Positive,TP):一个样本的真实类别为𝑐 并且模型正确地预测为类别𝑐.这类样本数量记为
- 假负例(False Negative,FN):一个样本的真实类别为𝑐,模型错误地预测为其他类.这类样本数量记为
- 假正例(False Positive,FP):一个样本的真实类别为其他类,模型错误地预测为类别𝑐.这类样本数量记为
- 真负例(True Negative,TN):一个样本的真实类别为其他类,模型也预测为其他类.这类样本数量记为𝑇𝑁𝑐.对于类别𝑐 来说,这种情况一般不需要关注.
这四种情况可以用下表表示
精确率(Precision),也叫精度或查准率,类别𝑐 的查准率是所有预测为类别𝑐 的样本中预测正确的比例:
召回率(Recall),也叫查全率,类别𝑐 的查全率是所有真实标签为类别𝑐 的样本中预测正确的比例:
F 值(F Measure)是一个综合指标,为精确率和召回率的调和平均:
ℱ𝑐 = \frac{(1 + 𝛽^2) × P_c × R_c} {𝛽^2 × P_c + R_c}
其中𝛽 用于平衡精确率和召回率的重要性,一般取值为1.𝛽 = 1 时的F 值称为F1值,是精确率和召回率的调和平均.
2.7.4 宏平均和微平均
为了计算分类算法在所有类别上的总体精确率、召回率和F1值,经常使用两种平均方法,分别称为宏平均(Macro Average)和微平均
宏平均是每一类的性能指标的算术平均值
微平均是每一个样本的性能指标的算术平均值
2.7.5 交叉验证
交叉验证(Cross-Validation)是一种比较好的衡量机器学习模型的统计分析方法,可以有效避免划分训练集和测试集时的随机性对评价结果造成的影响.我们可以把原始数据集平均分为𝐾组不重复的子集,每次选𝐾 − 1组子集作为训练集,剩下的一组子集作为验证集.这样可以进行𝐾 次试验并得到𝐾 个模型,将这𝐾 个模型在各自验证集上的错误率的平均作为分类器的评价.
2.8 理论和定理
2.8.1 PAC学习理论
希望有一套理论能够分析问题难度、计算模型能力,为学习算法提供理论保证,并指导机器学习模型和学习算法的设计.这就是计算学习理论.计算学习理论(Computational Learning Theory)是机器学习的理论基础,其中最基础的理论就是可能近似正确(Probably Approximately Correct,PAC)学习理论.
机器学习中一个很关键的问题是期望错误和经验错误之间的差异,称为泛化错误(Generalization Error)泛化错误可以衡量一个机器学习模型𝑓 是否可以很好地泛化到未知数据.
根据大数定律,当训练集大小|𝒟| 趋向于无穷大时,泛化错误趋向于0,即经验风险趋近于期望风险.
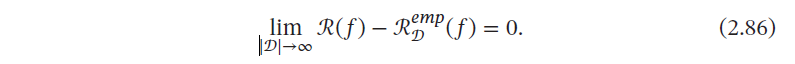
期望从有限的训练样本上学习到一个期望错误为0 的函数𝑓(𝒙) 是不切实际的.因此,需要降低对学习算法能力的期望,只要求学习算法可以以一定的概率学习到一个近似正确的假设,即PAC 学习(PAC Learning).一个PAC 可学习(PAC-Learnable)的算法是指该学习算法能够在多项式时间内从合理数量的训练数据中学习到一个近似正确的𝑓(𝒙).
PAC 学习可以分为两部分:
- 近似正确(Approximately Correct):一个假设𝑓 ∈ ℱ 是“近似正确”的,是指其在泛化错误𝒢𝒟 (𝑓) 小于一个界限𝜖.𝜖 一般为0 到1/2之间的数,0 < 𝜖 <1/2.如果𝒢𝒟 (𝑓) 比较大,说明模型不能用来做正确的“预测”.
- 可能(Probably):一个学习算法A有“可能”以1 − 𝛿 的概率学习到这样一个“近似正确”的假设.𝛿 一般为0 到1/2之间的数,0 < 𝛿 < 1/2
PAC 学习可以下面公式描述:
𝑃((R(𝑓) − R^{𝑒𝑚𝑝}_D (𝑓)) ≤ 𝜖) ≥ 1 − 𝛿
如果固定𝜖,𝛿,可以反过来计算出需要的样本数量
𝑁(𝜖, 𝛿) ≥ \frac 1 {2𝜖^2} (log |F| + log 2𝛿),
其中|ℱ| 为假设空间的大小.从上面公式可以看出,模型越复杂,即假设空间ℱ 越大,模型的泛化能力越差.要达到相同的泛化能力,越复杂的模型需要的样本数量越多.
2.8.2 没有免费的午餐定理
没有免费午餐定理证明:对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效.
没有免费午餐定理对于机器学习算法也同样适用.不存在一种机器学习算法适合于任何领域或任务.如果有人宣称自己的模型在所有问题上都好于其他模型,那么他肯定是在吹牛.
2.8.3 奥卡姆剃刀原理
奥卡姆剃刀(Occam’s Razor)原理是由14世纪逻辑学家William of Occam提出的一个解决问题的法则:“如无必要,勿增实体”.
奥卡姆剃刀的思想和机器学习中的正则化思想十分类似:简单的模型泛化能力更好.如果有两个性能相近的模型,我们应该选择更简单的模型.
2.8.4 丑小鸭定理
“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”.
世界上不存在相似性的客观标准,一切相似性的标准都是主观的.如果从体型大小或外貌的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果从基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间的差别.
2.8.5 归纳偏置
在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置(Inductive Bias).比如在最近邻分类器中,我们会假设在特征空间中,一个小的局部区域中的大部分样本同属一类.在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是互相独立的.
归纳偏置在贝叶斯学习中也经常称为先验(Prior).