val stream: DataStream[SensorReading] = ... val r = stream.assignTimestampAndWatermarks( newBoundedOutOfOrdernessTimestampExtractor[SensorReading](Times.seconds(10)){ overridedefextractTimestamp(e: SensorReading): Long = e.timestamp } )
/** * Assigns timestamps to records and emits a watermark for each reading with sensorId == "sensor_1". */ classPunctuatedAssignerextendsAssignerWithPunctuatedWatermarks[SensorReading] {
// 1 min in ms val bound: Long = 60 * 1000
// 如果该方法返回一个非空、且大于之前值的水位线,算子会将这个新水位线发出 overridedefcheckAndGetNextWatermark(r: SensorReading, extractedTS: Long): Watermark = { if (r.id == "sensor_1") { // emit watermark if reading is from sensor_1 newWatermark(extractedTS - bound) } else { // do not emit a watermark null } } // 生成时间戳 overridedefextractTimestamp(r: SensorReading, previousTS: Long): Long = { // assign record timestamp r.timestamp } }
/** * A keyed function that processes elements of a stream. * * @param <K> Type of the key. * @param <I> Type of the input elements. * @param <O> Type of the output elements. */ @PublicEvolving publicabstractclassKeyedProcessFunction<K, I, O> extendsAbstractRichFunction{
privatestaticfinallong serialVersionUID = 1L;
publicabstractvoidprocessElement( I value, Context ctx, Collector<O> out)throws Exception;
publicvoidonTimer( long timestamp, OnTimerContext ctx, Collector<O> out)throws Exception {}
/** * Information available in an invocation of {@link #processElement(Object, Context, Collector)} * or {@link #onTimer(long, OnTimerContext, Collector)}. */ publicabstractclassContext{
publicabstract Long timestamp(); publicabstract TimerService timerService();
publicabstract <X> voidoutput(OutputTag<X> outputTag, X value);
publicabstract K getCurrentKey(); }
/** * Information available in an invocation of {@link #onTimer(long, OnTimerContext, Collector)}. */ publicabstractclassOnTimerContextextendsContext{
// set up the streaming execution environment val env = StreamExecutionEnvironment.getExecutionEnvironment
// use event time for the application env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
// ingest sensor stream val readings: DataStream[SensorReading] = env // SensorSource generates random temperature readings .addSource(newSensorSource)
val warnings = readings // key by sensor id .keyBy(_.id) // 调用KeyedProcessFunction的具体实现TempIncreaseAlertFunction .process(newTempIncreaseAlertFunction)
warnings.print()
env.execute("Monitor sensor temperatures.") } }
/** Emits a warning if the temperature of a sensor * monotonically increases for 1 second (in processing time). */ classTempIncreaseAlertFunction extendsKeyedProcessFunction[String, SensorReading, String] {
// get previous temperature val prevTemp = lastTemp.value() // update last temperature lastTemp.update(r.temperature)
val curTimerTimestamp = currentTimer.value() // 这个计时器的第一个事件到来了,不做任何处理 if (prevTemp == 0.0) { // first sensor reading for this key. // we cannot compare it with a previous value. } // 如果新的温度小于老的温度,在上下文中注销计时器并且清空保存的计时器状态 elseif (r.temperature < prevTemp) { // temperature decreased. Delete current timer. ctx.timerService().deleteProcessingTimeTimer(curTimerTimestamp) currentTimer.clear() } // 如果新的温度大于老的温度并且当前没有计时器,就创建一个1s后触发的计时器并且保存到内部状态里面 elseif (r.temperature > prevTemp && curTimerTimestamp == 0) { // temperature increased and we have not set a timer yet. // set timer for now + 1 second val timerTs = ctx.timerService().currentProcessingTime() + 1000 ctx.timerService().registerProcessingTimeTimer(timerTs) // remember current timer currentTimer.update(timerTs) } } /**当计时器触发时会调用这个函数*/ overridedefonTimer( ts: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = { // 把这个事件的String放到输出中,相当于发出了一条警报 out.collect("Temperature of sensor '" + ctx.getCurrentKey + "' monotonically increased for 1 second.") // 清空计时器状态 currentTimer.clear() } }
// ingest sensor stream val readings: DataStream[SensorReading] = ...
val monitoredReadings: DataStream[SensorReading] = readings // monitor stream for readings with freezing temperatures // 调用处理函数 .process(newFreezingMonitor)
// retrieve and print the freezing alarms monitoredReadings .getSideOutput(newOutputTag[String]("freezing-alarms")) .print()
// print the main output readings.print()
env.execute() } }
/** Emits freezing alarms to a side output for readings with a temperature below 32F. */ classFreezingMonitorextendsProcessFunction[SensorReading, SensorReading] {
// define a side output tag // 定义一个副输出标签 lazyval freezingAlarmOutput: OutputTag[String] = newOutputTag[String]("freezing-alarms") // 处理每个元素的方法 overridedefprocessElement( r: SensorReading, ctx: ProcessFunction[SensorReading, SensorReading]#Context, out: Collector[SensorReading]): Unit = { // 如果SensorReading的温度小于32F则放入Freezing Alarm副输出 // emit freezing alarm if temperature is below 32F. if (r.temperature < 32.0) { ctx.output(freezingAlarmOutput, s"Freezing Alarm for ${r.id}") } // 所有的SensorReading都output到常规输出 // forward all readings to the regular output out.collect(r) } }
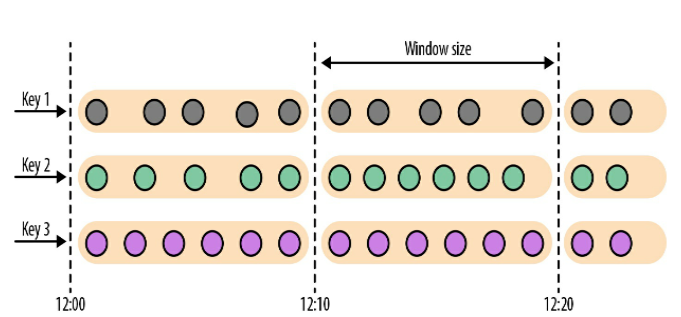
val avgTemp = sensorData .keyBy(_.id) // group readings in 1 hour windows with 15 min offset .window(TumblingEventTimeWindows.of(Time.hours(1), Time.minutes(15))) .process(newTemperatureAverager)
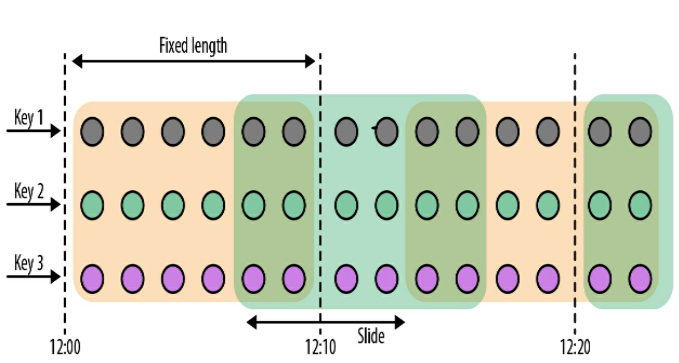
// 事件时间 // event-time sliding windows assigner val slidingAvgTemp = sensorData .keyBy(_.id) // create 1h event-time windows every 15 minutes .window(SlidingEventTimeWindows.of(Time.hours(1), Time.minutes(15))) .process(newTemperatureAverager)
// 处理时间 // processing-time sliding windows assigner val slidingAvgTemp = sensorData .keyBy(_.id) // create 1h processing-time windows every 15 minutes .window(SlidingProcessingTimeWindows.of(Time.hours(1), Time.minutes(15))) .process(newTemperatureAverager)
// 简写 // sliding windows assigner using a shortcut method val slidingAvgTemp = sensorData .keyBy(_.id) // shortcut for window.(SlidingEventTimeWindow.of(size, slide)) .timeWindow(Time.hours(1), Time(minutes(15))) .process(newTemperatureAverager)
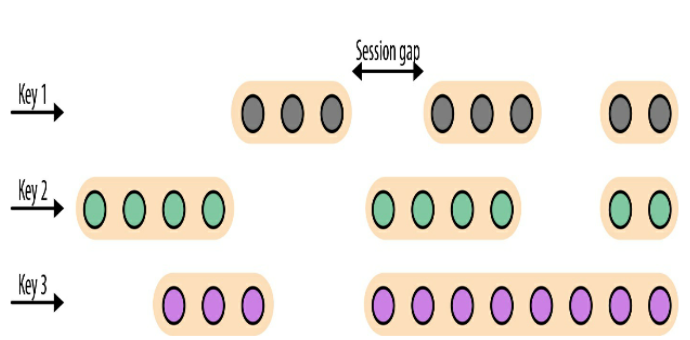
/** session gap 设置为15分钟*/ // event-time session windows assigner val sessionWindows = sensorData .keyBy(_.id) // create event-time session windows with a 15 min gap .window(EventTimeSessionWindows.withGap(Time.minutes(15))) .process(...)
// processing-time session windows assigner val sessionWindows = sensorData .keyBy(_.id) // create processing-time session windows with a 15 min gap .window(ProcessingTimeSessionWindows.withGap(Time.minutes(15))) .process(...)
// State accessor for per-window state 每个窗口的状态 publicabstract KeyedStateStore windowState();
// State accessor for per-key global state 每个键的全局状态 publicabstract KeyedStateStore globalState();
// Emits a record to the side output identified by the OutputTag. // 向OutputTag标识的副输出发送记录 publicabstract <X> voidoutput(OutputTag<X> outputTag, X value); } }
// output the lowest and highest temperature reading every 5 seconds val minMaxTempPerWindow: DataStream[MinMaxTemp] = sensorData // 这里keyBy中key的类型需要与ProcessWindowFunction的KEY类型参数一致 .keyBy(_.id) .timeWindow(Time.seconds(5)) .process(newHighAndLowTempProcessFunction)
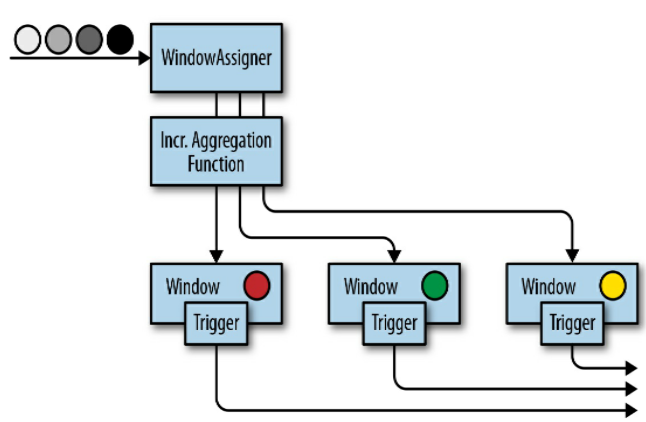
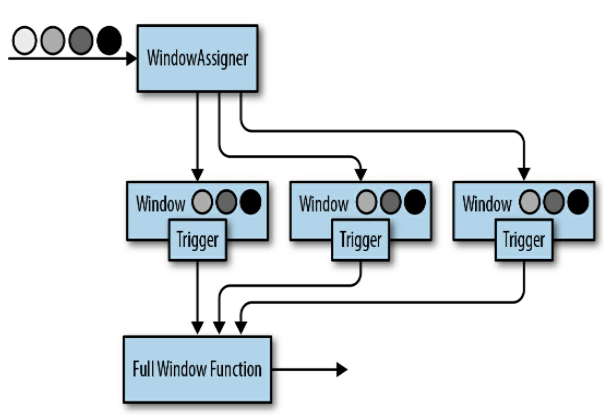
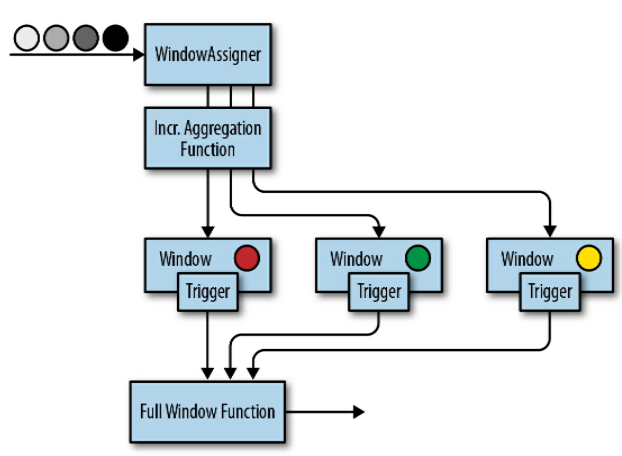
// T: 流中的元素类型 // W: 窗口元数据类型 publicabstractclassWindowAssigner<T, WextendsWindow> implementsSerializable{ // Returns a collection of windows to which the element is assigned // 返回元素分配的目标窗口集合 publicabstract Collection<W> assignWindows(T element, long timestamp, WindowAssignerContext context); // 返回窗口分配器的默认触发器(用于算子没有显式指定触发器的情况) publicabstract Trigger<T, W> getDefaultTrigger(StreamExecutionEnvironment env); // Returns the TypeSerializer for the windows of this WindowAssigner publicabstract TypeSerializer<W> getWindowSerializer(ExecutionConfig executionConfig); // 判断这个窗口分配器使用的是不是事件时间 publicabstractbooleanisEventTime(); // 窗口分配器的上下文 publicabstractstaticclassWindowAssignerContext{ // 返回当前处理时间 publicabstractlonggetCurrentProcessingTime(); } }
publicabstractclassTrigger<T, WextendsWindow> implementsSerializable{ // 每当有元素被添加到窗口时,这个方法都会被调用 // Called for every element that gets added to a window TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx); // 当一个处理时间计时器触发时调用 // Called when a processing-time timer fires publicabstract TriggerResult onProcessingTime(long timestamp, W window, TriggerContext ctx); // 当一个事件时间计时器触发时调用 // Called when an event-time timer fires publicabstract TriggerResult onEventTime(long timestamp, W window, TriggerContext ctx); // 返回触发器是否支持状态的合并 // Returns true if this trigger supports merging of trigger state publicbooleancanMerge(); // 当多个窗口需要合并时调用,多个窗口中触发器的状态也要被合并 // Called when several windows have been merged into one window // and the state of the triggers needs to be merged publicvoidonMerge(W window, OnMergeContext ctx); // 这个方法会在一个窗口被清除时调用,它应该清除触发器自定义的各种 // Clears any state that the trigger might hold for the given window // This method is called when a window is purged publicabstractvoidclear(W window, TriggerContext ctx);
// 用于触发器中方法的上下文对象 // A context object that is given to Trigger methods to allow them // to register timer callbacks and deal with state publicinterfaceTriggerContext{ // 获取当前处理时间 // Returns the current processing time longgetCurrentProcessingTime(); // 获取当前水位线 // Returns the current watermark time longgetCurrentWatermark(); // 注册处理时间计时器 // Registers a processing-time timer voidregisterProcessingTimeTimer(long time); // 注册事件时间计时器 // Registers an event-time timer voidregisterEventTimeTimer(long time); // 删除处理时间计时器 // Deletes a processing-time timer voiddeleteProcessingTimeTimer(long time); // 删除事件时间计时器 // Deletes an event-time timer voiddeleteEventTimeTimer(long time); // 获取一个作用域为触发器键值和当前窗口的状态对象 // Retrieves a state object that is scoped to the window and the key of the trigger <S extends State> S getPartitionedState(StateDescriptor<S, ?> stateDescriptor); }
// 用于onMerge方法的特殊上下文 // Extension of TriggerContext that is given to the Trigger.onMerge() method publicinterfaceOnMergeContextextendsTriggerContext{ // Merges per-window state of the trigger // The state to be merged must support merging voidmergePartitionedState(StateDescriptor<S, ?> stateDescriptor); } }
// firstSeen是一个Boolean类型的状态,初始值为false // firstSeen will be false if not set yet val firstSeen: ValueState[Boolean] = ctx.getPartitionedState( newValueStateDescriptor[Boolean]("firstSeen", classOf[Boolean])) // 当第一个事件到达时,注册两个计时器 // register initial timer only for first element if (!firstSeen.value()) { // compute time for next early firing by rounding watermark to second val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000)) // 注册第一个计时器,当前水位线+1s ctx.registerEventTimeTimer(t) // 注册第二个计时器,当前窗口的结束时间 // register timer for the window end ctx.registerEventTimeTimer(window.getEnd) // 更新firstSeen状态为true firstSeen.update(true) } // 返回Continue,意思是什么都不做 // Continue. Do not evaluate per element TriggerResult.CONTINUE }
// 当事件时间计时器触发时,这个方法被调用 overridedefonEventTime( timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = { // 如果是窗口的结束时间的那个计时器 if (timestamp == window.getEnd) { // 执行计算并且清除窗口 // final evaluation and purge window state TriggerResult.FIRE_AND_PURGE // 如果+1s的计时器 } else { // register next early firing timer // 先注册下一个计时器,还是+1s val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000)) if (t < window.getEnd) { ctx.registerEventTimeTimer(t) } // 执行计算 // fire trigger to evaluate window TriggerResult.FIRE } }
// 当处理时间计时器触发时,这个方法被调用,没啥用 overridedefonProcessingTime( timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = { // Continue. We don't use processing time timers TriggerResult.CONTINUE }
// 当窗口要被删除时,这个方法被调用,我们需要手动清理firstSeen状态 overridedefclear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {
// clear trigger state val firstSeen: ValueState[Boolean] = ctx.getPartitionedState( newValueStateDescriptor[Boolean]("firstSeen", classOf[Boolean])) firstSeen.clear() } }
6.3.4.4 移除器
在Flink的窗口机制中,移除器是一个可选组件。它可以在窗口函数计算之前或之后删除窗口中的元素。
下面示例展示了Evictor接口的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
publicinterfaceEvictor<T, WextendsWindow> extendsSerializable{ // Optionally evicts elements. Called before windowing function. voidevictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext); // Optionally evicts elements. Called after windowing function. voidevictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
// A context object that is given to Evictor methods. interfaceEvictorContext{ // Returns the current processing time. longgetCurrentProcessingTime(); // Returns the current event time watermark. longgetCurrentWatermark(); } }
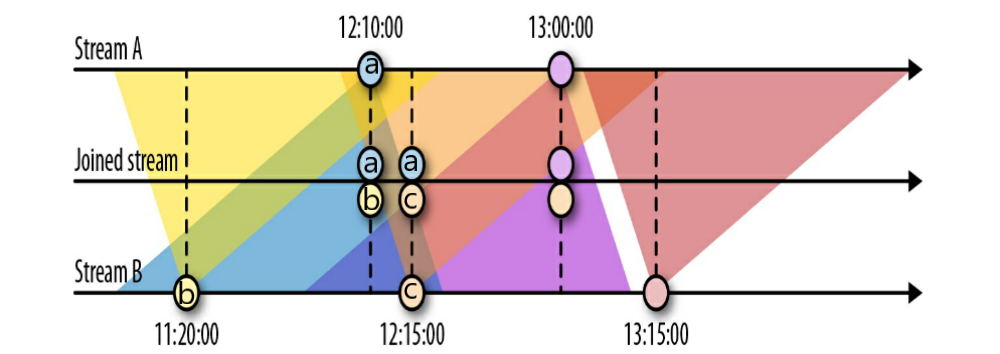
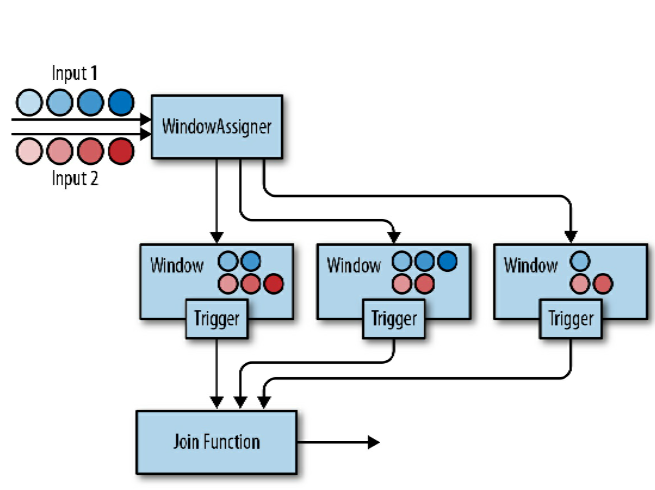
6.4 Joining Streams on Time
在处理流时,一个常见的需求是connect or join the events of two streams。Flink的DataStream API提供了两个内置的算子:Interval join 和 Window join。在本节中,我们将描述这两个算子。
// 处理正常流 val filteredReadings: DataStream[SensorReading] = readings .process(newLateReadingsFilter)
// 取出副输出 val lateReadings: DataStream[SensorReading] = filteredReadings .getSideOutput(lateReadingsOutput)
// 对正常流进行后续处理 print the filtered stream filteredReadings.print()
// 对副输出进行后续处理 print messages for late readings lateReadings .map(r => "*** late reading *** " + r.id) .print()
/** A ProcessFunction that filters out late sensor readings and re-directs them to a side output */ classLateReadingsFilterextendsProcessFunction[SensorReading, SensorReading] {
// compare record timestamp with current watermark if (r.timestamp < ctx.timerService().currentWatermark()) { // this is a late reading => redirect it to the side output // 迟到的事件重定向到副输出中 ctx.output(LateDataHandling.lateReadingsOutput, r) } else { // 正常的事件直接输出 out.collect(r) } } }
val readings: DataStream[SensorReading] = ??? val countPer10Secs: DataStream[(String, Long, Int, String)] = readings .keyBy(_.id) .timeWindow(Time.seconds(10)) // process late readings for 5 additional seconds 设置延迟容忍度为5s .allowedLateness(Time.seconds(5)) // count readings and update results if late readings arrive .process(newUpdatingWindowCountFunction)
/**这个处理函数会采用Update策略处理迟到事件*/ classUpdatingWindowCountFunctionextendsProcessWindowFunction[SensorReading, (String, Long, Int, String), String, TimeWindow] { overridedefprocess( id: String, ctx: Context, elements: Iterable[SensorReading], out: Collector[(String, Long, Int, String)]): Unit = { // count the number of readings val cnt = elements.count(_ => true) // 这个状态用来标记是否是首次计算 val isUpdate = ctx.windowState.getState( newValueStateDescriptor[Boolean]("isUpdate", Types.of[Boolean])) if (!isUpdate.value()) { // 首次计算并发出结果 out.collect((id, ctx.window.getEnd, cnt, "first")) isUpdate.update(true) } else { // 不是首次计算,发出更新 out.collect((id, ctx.window.getEnd, cnt, "update")) } } }