第3章 线性模型
正确的判断来自于经验,而经验来自于错误的判断.——弗雷德里克·布鲁克斯
线性模型(Linear Model)是指通过样本特征的线性组合来进行预测的模型
其中 为𝐷 维的权重向量,𝑏 为偏置.
线性回归就是典型的线性模型,直接用𝑓(𝒙; 𝒘) 来预测输出目标𝑦 .
在分类问题中,由于输出目标𝑦 是一些离散的标签,而𝑓(𝒙; 𝒘) 的值域为实数,因此无法直接用𝑓(𝒙; 𝒘) 来进行预测,需要引入一个非线性的决策函数(Decision Function)𝑔(⋅) 来预测输出目标
𝑓(𝒙; 𝒘)称为判别函数(Discriminant Function)
下图定义了一个典型的二分类的决策函数
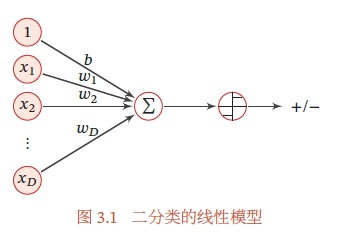
在本章,我们主要介绍四种不同线性分类模型:Logistic 回归、Softmax 回归、感知器和支持向量机,这些模型的区别主要在于使用了不同的损失函数.
3.1 线性判别函数和决策边界
3.1.1 二分类
二分类(Binary Classification)问题的类别标签𝑦 只有两种取值,通常可以设为{+1, −1} 或{0, 1}.在二分类问题中,常用正例(Positive Sample)和负例(Negative Sample)来分别表示属于类别+1 和−1 的样本.
特征空间 中所有满足𝑓(𝒙; 𝒘) = 0 的点组成一个分割超平面(Hyperplane),称为决策边界(Decision Boundary)或决策平面(Decision Surface).决策边界将特征空间一分为二,划分成两个区域,每个区域对应一个类别.
超平面就是三维空间中的平面在更高维空间的推广.𝐷 维空间中的超平面是𝐷 − 1 维的.
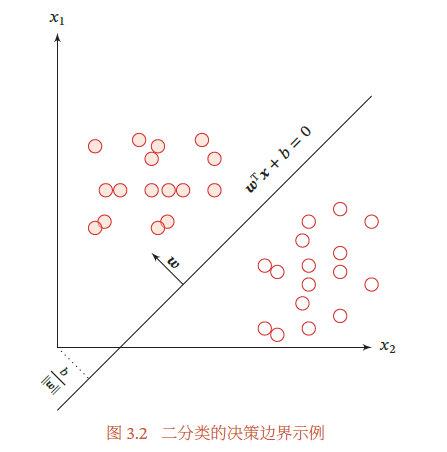
“线性分类模型”就是指其决策边界是线性超平面.在特征空间中,决策平面与权重向量𝒘 正交.特征空间中每个样本点到决策平面的有向距离(Signed Distance)为𝛾 = \frac {𝑓(x; w)} {‖w‖}
下图给出了二分类问题的线性决策边界示例,,其中样本特征向量𝒙 = [𝑥1, 𝑥2],权重向量𝒘 = [𝑤1, 𝑤2].
定义3.1 – 两类线性可分:对于训练集,如果存在权重向量𝒘∗,对所有样本都满足𝑦𝑓(𝒙; 𝒘∗) > 0,那么训练集𝒟 是线性可分的.
为了学习参数𝒘,我们需要定义合适的损失函数以及优化方法.对于二分类问题,最直接的损失函数为0-1 损失函数,.但0-1 损失函数的数学性质不好,其关于𝒘 的导数为0,从而导致无法优化𝒘.
3.1.2 多分类
多分类(Multi-class Classification)问题是指分类的类别数𝐶 大于2.多分类一般需要多个线性判别函数
假设一个多分类问题的类别为{1, 2, ⋯ , 𝐶},常用的方式有以下三种
- “一对其余”方式:把多分类问题转换为𝐶 个“一对其余”的二分类问题.这种方式共需要𝐶 个判别函数,其中第𝑐 个判别函数𝑓𝑐 是将类别𝑐 的样本和不属于类别𝑐 的样本分开.
- “一对一”方式:把多分类问题转换为𝐶(𝐶 − 1)/2 个**“一对一”的二分类问题.这种方式共需要𝐶(𝐶 − 1)/2 个判别函数**
- “argmax”方式:这是一种改进的**“一对其余”方式,共需要𝐶 个判别函数**
对于样本𝒙,如果存在一个类别𝑐,相对于所有的其他类别𝑐(̃ 𝑐 ̃ ≠ 𝑐)有𝑓𝑐(𝒙;𝒘𝑐) > 𝑓𝑐(̃𝒙,𝒘𝑐(̃),那么𝒙属于类别𝑐.“argmax”方式的预测函数定义为

3.2 Logistic回归
为了解决连续的线性函数不适合进行分类的问题,我们引入非线性函数 来预测类别标签的后验概率.
其中𝑔(⋅) 通常称为激活函数(Activation Function),其作用是把线性函数的值域从实数区间“挤压”到了**(0, 1)** 之间,可以用来表示概率.
在Logistic 回归中,我们使用Logistic 函数来作为激活函数.标签𝑦 = 1 的后验概率为
𝑝(𝑦 = 1|𝒙) = 𝜎(𝒘T𝒙) ≜ \frac 1 {1 + exp(−𝒘^T𝒙)}
Logistic 函数定义为
当参数为(𝑘 = 1, , 𝐿 = 1) 时,Logistic 函数称为标准Logistic 函数,记为𝜎(𝑥).
𝜎(𝑥) = \frac 1 {1 + exp(−𝑥)}
标准Logistic 函数在机器学习中使用得非常广泛,经常用来将一个实数空间的数映射到(0, 1) 区间.
标准Logistic 函数的导数为
𝜎′(𝑥) = 𝜎(𝑥)(1 − 𝜎(𝑥))
将上文公式变换可得
其中为样本𝒙 为正反例后验概率的比值,称为几率(Odds),几率的对数称为对数几率(Log Odds,或Logit).公式(3.17) 中等号的左边是线性函数,这样Logistic 回归可以看作预测值为“标签的对数几率”的线性回归模型.因此,Logistic 回归也称为对数几率回归(Logit Regression).
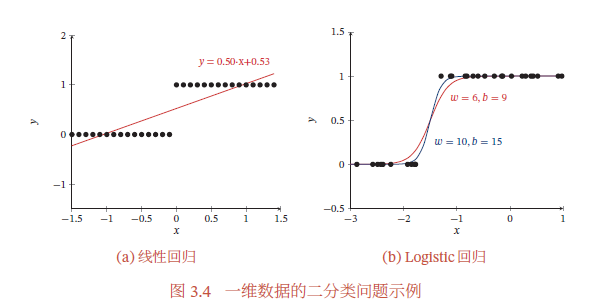
下图给出了使用线性回归和Logistic回归来解决一维数据的二分类问题的示例
3.2.1 参数学习
Logistic 回归采用交叉熵作为损失函数,并使用梯度下降法来对参数进行优化.
具体略
3.3 Softmax回归
Softmax 回归(Softmax Regression),也称为多项(Multinomial)或多类(Multi-Class)的Logistic 回归,是Logistic 回归在多分类问题上的推广.
Softmax函数可以将多个标量映射为一个概率分布.对于𝐾 个标量,Softmax 函数定义为
这样就可以将𝐾 个标量 转换为一个分布:,满足
对于多类问题,类别标签𝑦 ∈ {1, 2, ⋯ , 𝐶} 可以有𝐶 个取值.给定一个样本𝒙,Softmax 回归预测的属于类别𝑐 的条件概率为
Softmax 回归的决策函数可以表示为
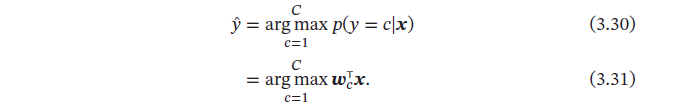
3.3.1 向量表示
上问公式用向量形式可以写为
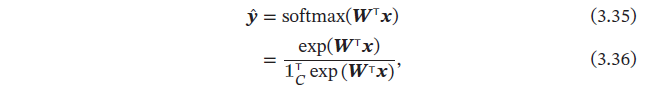
其中 是由𝐶 个类的权重向量组成的矩阵, 为𝐶 维的全1 向量,为所有类别的预测条件概率组成的向量,第𝑐维的值是第𝑐类的预测条件概率.
3.3.2 参数学习
给定𝑁 个训练样本,Softmax 回归使用交叉熵损失函数来学习最优的参数矩阵𝑾.为了方便起见,我们用𝐶 维的one-hot 向量 来表示类别标签.
具体损失函数,导数计算,优化过程略
3.4 感知器
感知器(Perceptron)由Frank Roseblatt 于1957 年提出,是一种广泛使用的线性分类器.感知器可谓是最简单的人工神经网络,只有一个神经元.
感知器是一种简单的两类线性分类模型,其分类准则
3.4.1 参数学习
给定𝑁 个样本的训练集:,其中,感知器学习算法试图找到一组参数𝒘∗,使得对于每个样本(𝒙(𝑛), 𝑦(𝑛)) 有
感知器的学习算法是一种错误驱动的在线学习算法.先初始化一个权重向量𝒘 ← 0(通常是全零向量),然后每次分错一个样本(𝒙, 𝑦)
时,即,就用这个样本来更新权重.
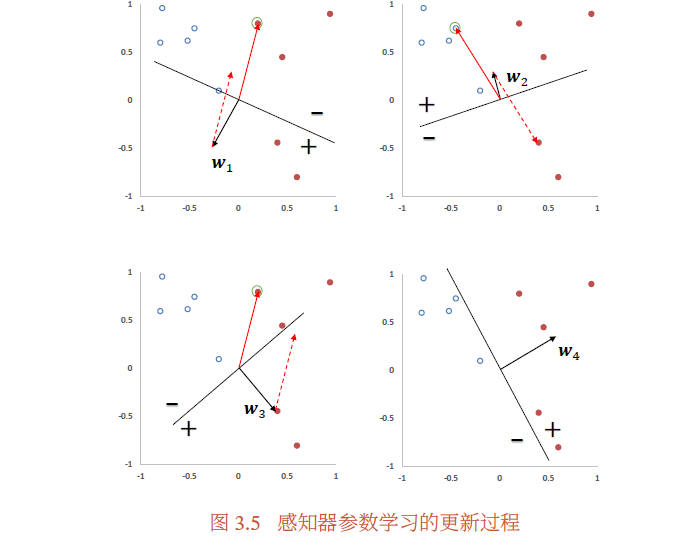
具体的感知器参数学习策略如算法3.1所示

图3.5给出了感知器参数学习的更新过程,其中红色实心点为正例,蓝色空心点为负例.黑色箭头表示当前的权重向量,红色虚线箭头表示权重的更新方向.
3.4.2 感知器的收敛性
对于两类问题,如果训练集是线性可分的,那么感知器算法可以在有限次迭代后收敛.
定理3.1 – 感知器收敛性:给定训练集,令𝑅 是训练集
中最大的特征向量的模,即
如果训练集𝒟 线性可分,则存在一个正的常数𝛾(𝛾 > 0) 和权重向量𝒘∗,并且‖𝒘∗‖ = 1,对所有𝑛 都满足(𝒘^∗)^T(𝑦^{(𝑛)}𝒙^{(𝑛)}) ≥ 𝛾,且权重更新次数不超过\frac {R^2}{𝛾^2} .
感知器在线性可分的数据上可以保证收敛,但其存在以下不足:
- 在数据集线性可分时,感知器虽然可以找到一个超平面把两类数据分开,但并不能保证其泛化能力.
- 感知器对样本顺序比较敏感.每次迭代的顺序不一致时,找到的分割超平面也往往不一致.
- 如果训练集不是线性可分的,就永远不会收敛.
3.4.3 参数平均感知器
感知器学习到的权重向量和训练样本的顺序相关.在迭代次序上排在后面的错误样本比前面的错误样本,对最终的权重向量影响更大.
为了提高感知器的鲁棒性和泛化能力,我们可以将在感知器学习过程中的所有𝐾 个权重向量保存起来,并赋予每个权重向量 一个置信系数.最终的分类结果通过这𝐾 个不同权重的感知器投票决定,这个模型也称为投票感知器.
令𝜏_k 为第𝑘 次更新权重 时的迭代次数(即训练过的样本数量),𝜏_{k+1} 为下次权重更新时的迭代次数,则权重 的置信系数设置为从𝜏_k 到𝜏_{k+1} 之间间隔的迭代次数,即c_k = 𝜏_{k+1} − 𝜏_k.置信系数 越大,说明权重在之后的训练过程中正确分类样本的数量越多,越值得信赖.
投票感知器需要保存𝐾 个权重向量,增加开销.因此,人们经常会使用一个简化的版本,通过使用“参数平均”的策略来减少投票感知器的参数数量,也叫作平均感知器。这个方法非常简单,只需要在算法3.1中增加一个𝒘̄,并且在每次迭代时都更新𝒘̄:为了提高迭代速度,有很多改进的方法,让这个更新只需要在错误预测发生时才进行更新.

3.4.4 扩展到多分类
为了使得感知器可以处理更复杂的输出,我们引入一个构建在输入输出联合空间上的特征函数𝜙(𝒙, 𝒚),将样本对(𝒙, 𝒚) 映射到一个特征向量空间.
在联合特征空间中,我们可以建立一个广义的感知器模型
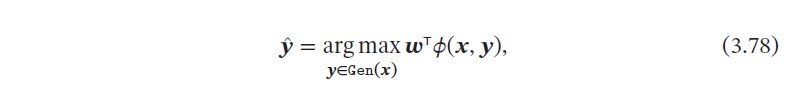
当用广义感知器模型来处理𝐶 分类问题时, 为类别的one-hot 向量表示.在C分类问题中,一种常用的特征函数𝜙(𝒙, 𝒚) 是𝒙 和𝒚 的外积,即
𝜙(𝒙, 𝒚) = vec(𝒙𝒚^T) ∈ ℝ^{(D×C)}
给定样本(𝒙, 𝒚),若,𝒚 为第𝑐 维为1 的one-hot 向量,则

广义感知器算法的训练过程如算法3.3所示.

广义感知器在满足广义线性可分条件下,也能保证在有限步骤内收敛
3.5 支持向量机
支持向量机(Support Vector Machine,SVM)是一个经典的二分类算法,其找到的分割超平面具有更好的鲁棒性,因此广泛使用在很多任务上,并表现出了很强优势.
给定一个二分类器数据集,其中,如果两类样本是线性可分的,即存在一个超平面将两类样本分开,那么对于每个样本都有.
数据集中每个样本𝒙(𝑛) 到分割超平面的距离为:
𝛾(𝑛) = \frac {|𝒘^Tx(n) + b|}{‖w‖} = \frac {𝑦(𝑛)(𝒘T𝒙(𝑛) + 𝑏)}{‖𝒘‖}
我们定义间隔(Margin)𝛾 为整个数据集𝐷 中所有样本到分割超平面的最短距离:
𝛾 = min_𝑛𝛾(𝑛)
如果间隔𝛾 越大,其分割超平面对两个数据集的划分越稳定,不容易受噪声等因素影响.支持向量机的目标是寻找一个超平面 使得𝛾 最大,即
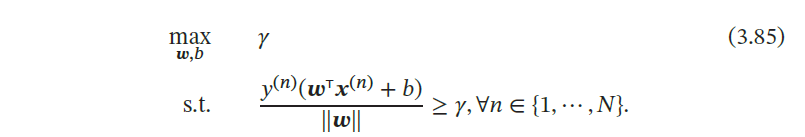
由于同时缩放𝒘 → 𝑘𝒘 和𝑏 → 𝑘𝑏 不会改变样本𝒙(𝑛) 到分割超平面的距离,我们可以限制‖𝒘‖ ⋅ 𝛾 = 1,则公式(3.85) 等价于
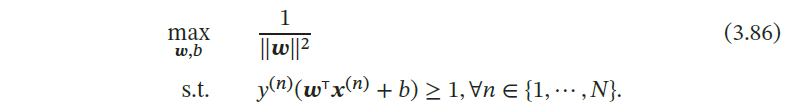
数据集中所有满足 的样本点,都称为支持向量
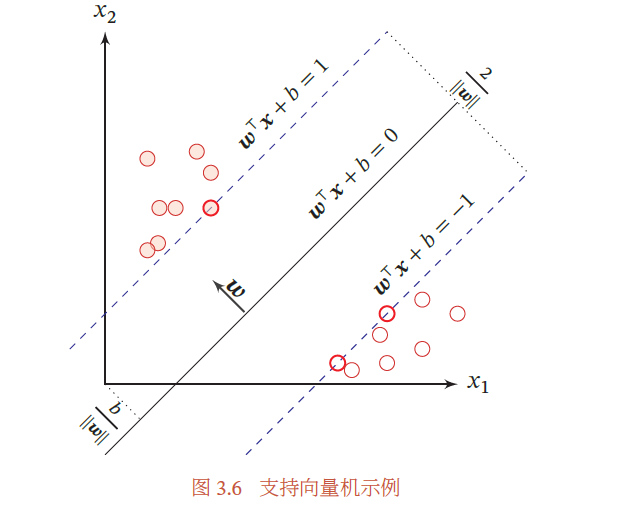
对于一个线性可分的数据集,其分割超平面有很多个,但是间隔最大的超平面是唯一的.图3.6给定了支持向量机的最大间隔分割超平面的示例,其中轮廓线加粗的样本点为支持向量.
3.5.1 参数学习
略,使用拉格朗日乘数法
支持向量机的目标函数可以通过SMO 等优化方法得到全局最优解,因此比其他分类器的学习效率更高.此外,支持向量机的决策函数只依赖于支持向量,与训练样本总数无关,分类速度比较快.
3.5.2 核函数
支持向量机还有一个重要的优点是可以使用核函数(Kernel Function)隐式地将样本从原始特征空间映射到更高维的空间,并解决原始特征空间中的线性不可分问题.
3.5.3 软间隔
在支持向量机的优化问题中,约束条件比较严格.如果训练集中的样本在特征空间中不是线性可分的,就无法找到最优解.为了能够容忍部分不满足约束的样本,我们可以引入松弛变量(Slack Variable)𝜉
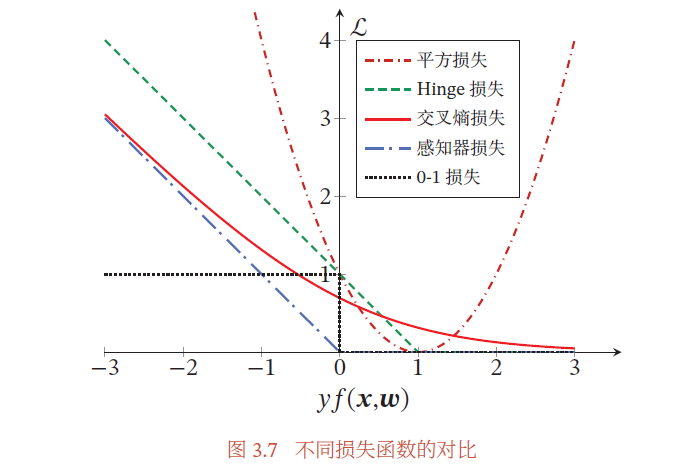
3.6 损失函数对比
图3.7给出了不同损失函数的对比.对于二分类来说,当𝑦𝑓(𝒙; 𝒘) > 0 时,分类器预测正确,并且𝑦𝑓(𝒙; 𝒘) 越大,模型的预测越正确;当𝑦𝑓(𝒙; 𝒘) < 0 时,分类器预测错误,并且𝑦𝑓(𝒙; 𝒘) 越小,模型的预测越错误.因此,一个好的损失函数应该随着𝑦𝑓(𝒙; 𝒘) 的增大而减少.(越错误惩罚越重,越正确越没有惩罚)从图3.7中看出,除了平方损失,其他损失函数都比较适合于二分类问题.