
第4章 前馈神经网络
神经网络是一种大规模的并行分布式处理器,天然具有存储并使用经验知识的能力.它从两个方面上模拟大脑:(1)网络
获取的知识是通过学习来获取的;(2)内部神经元的连接强度,即突触权重,用于储存获取的知识.
人工神经网络(Artificial Neural Network,ANN)是指一系列受生物学和神经科学启发的数学模型.这些模型主要是通过对人脑的神经元网络进行抽象,构建人工神经元,并按照一定拓扑结构来建立人工神经元之间的连接,来模拟生物神经网络.
神经网络最早是作为一种主要的连接主义模型.20 世纪80 年代中后期,最流行的一种连接主义模型是分布式并行处理
- 信息表示是分布式的(非局部的);
- 记忆和知识是存储在单元之间的连接上;
- 通过逐渐改变单元之间的连接强度来学习新的知识.
从机器学习的角度来看,神经网络一般可以看作一个非线性模型,其基本组成单元为具有非线性激活函数的神经元,通过大量神经元之间的连接,使得神经网络成为一种高度非线性的模型.神经元之间的连接权重就是需要学习的参数,可以在机器学习的框架下通过梯度下降方法来进行学习.
4.1 神经元
神经元(Neuron),是构成神经网络的基本单元。
一个生物神经元通常具有多个树突和一条轴突.
- 树突用来接收信息,轴突用来发送信息.
- 当神经元所获得的输入信号的积累超过某个阈值时,它就处于兴奋状态,产生电脉冲.
- 轴突尾端有许多末梢可以给其他神经元的树突产生连接(突触),并将电脉冲信号传递给其他神经元.
假设一个神经元接收𝐷 个输入𝑥1, 𝑥2, ⋯ , 𝑥𝐷,令向量𝒙 = [𝑥1; 𝑥2; ⋯ ; 𝑥𝐷] 来表示这组输入,并用净输入(Net Input)𝑧 ∈ ℝ 表示一个神经元所获得的输入信号𝒙 的加权和
其中 是𝐷 维的权重向量,𝑏 ∈ ℝ 是偏置.
净输入z 在经过一个非线性函数𝑓(⋅) 后,得到神经元的活性值(Activation)a,
其中非线性函数𝑓(⋅) 称为激活函数(Activation Function).
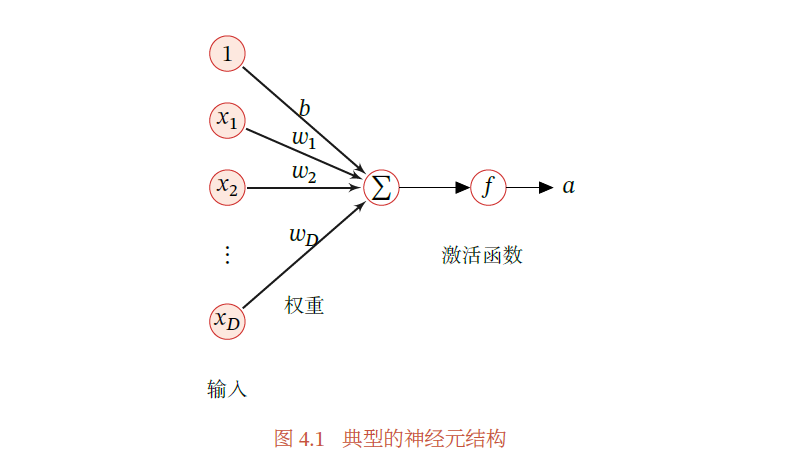
激活函数需要具有以下特征
- 连续并可导(允许少数点上不可导)的非线性函数.可导的激活函数可以直接利用数值优化的方法来学习网络参数.
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率.
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性.
4.1.1 Sigmoid型函数
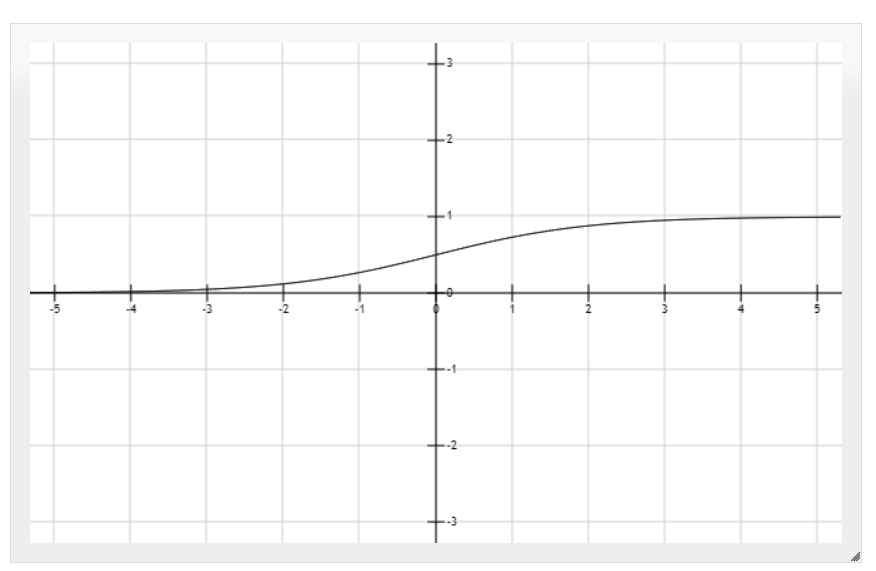
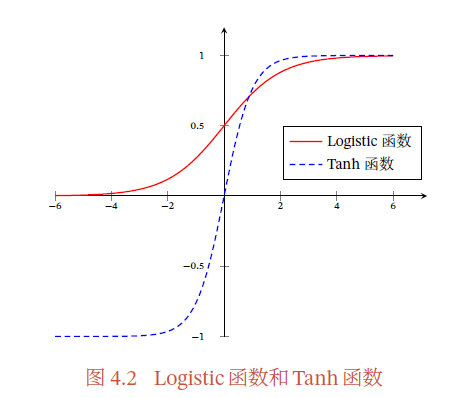
Sigmoid 型函数是指一类S 型曲线函数,为两端饱和函数.常用的Sigmoid型函数有Logistic 函数和Tanh 函数.
4.1.1.1 Logistic函数
Logistic 函数定义为
𝜎(𝑥) = \frac 1 {1 + exp(−x)}
Logistic 函数可以看成是一个**“挤压”函数**,把一个实数域的输入“挤压”到(0, 1).当输入值在0 附近时,Sigmoid 型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制.输入越小,越接近于0;输入越大,越接近于1.且Logistic函数连续并可导
因为Logistic 函数的性质,使得装备了Logistic 激活函数的神经元具有以下两点性质:
- 其输出直接可以看作概率分布,使得神经网络可以更好地和统计学习模型进行结合.
- 其可以看作一个软性门(Soft Gate),用来控制其他神经元输出信息的数量.
4.1.1.2 Tanh函数
Tanh 函数也是一种Sigmoid 型函数.其定义为
Tanh 函数可以看作放大并平移的Logistic 函数,其值域是(−1, 1).
Tanh 函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0.非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢.
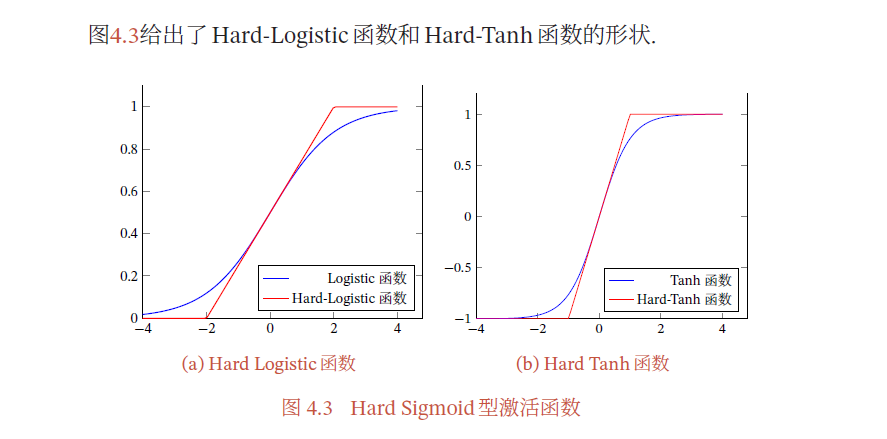
4.1.1.3 Hard-Logistic函数和Hard-Tanh函数
Logistic 函数和Tanh 函数都是Sigmoid 型函数,具有饱和性,但是计算开销较大.因为这两个函数都是在中间(0 附近)近似线性,两端饱和.因此,这两个函数可以通过分段函数来近似.
4.1.2 ReLU函数
ReLU(Rectified Linear Unit,修正线性单元)[Nair et al., 2010],也叫Rectifier 函数[Glorot et al., 2011],是目前深度神经网络中经常使用的激活函数.
ReLU 实际上是一个斜坡(ramp)函数,定义为
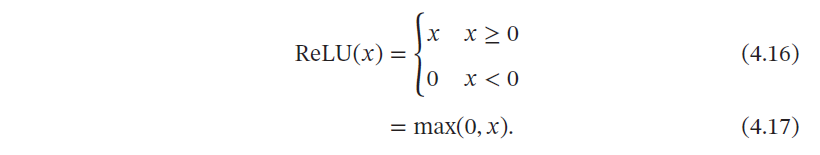
优点
- 采用ReLU 的神经元只需要进行加、乘和比较的操作,计算上更加高效.
- ReLU 函数也被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度可以非常高).
- 在优化方面,相比于Sigmoid 型函数的两端饱和,ReLU 函数为左饱和函数,且在𝑥 > 0 时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度.
缺点
- ReLU 函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率.
- ReLU 神经元在训练时比较容易“死亡”.在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU 神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活.这种现象称为死亡ReLU问题(Dying ReLU Problem),并且也有可能会发生在其他隐藏层.
在实际使用中,为了避免上述情况,有几种ReLU 的变种也会被广泛使用.
4.1.2.1 带泄露的ReLU
带泄露的ReLU(Leaky ReLU)在输入𝑥 < 0 时,也保持一个很小的梯度𝛾.这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免死亡ReLU问题
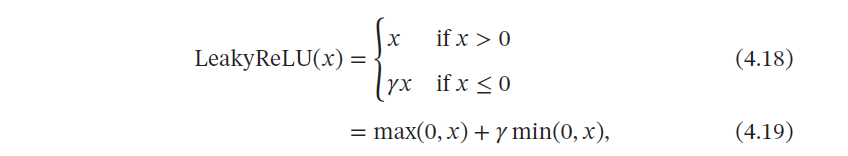
4.1.2.2 带参数的ReLU
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不同神经元可以有不同的参数[He et al., 2015].对于第𝑖 个神经元,其PReLU 的定义为
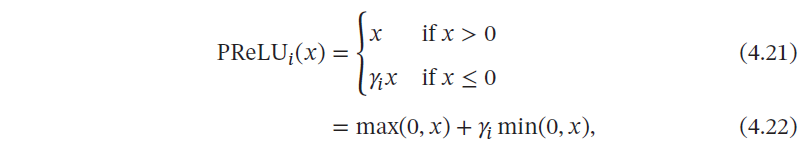
如果𝛾𝑖 = 0,那么PReLU 就退化为ReLU.如果𝛾𝑖 为一个很小的常数,则PReLU 可以看作带泄露的ReLU.PReLU 可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数.
4.1.2.3 ELU函数
ELU(Exponential Linear Unit,指数线性单元)是一个近似的零中心化的非线性函数,其定义为
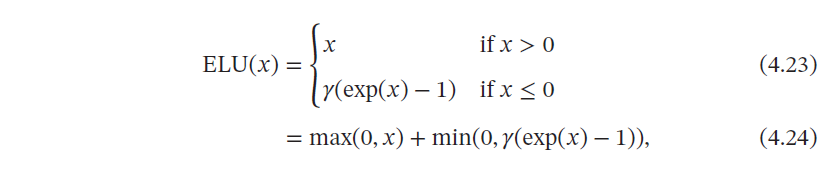
其中𝛾 ≥ 0 是一个超参数,决定𝑥 ≤ 0 时的饱和曲线,并调整输出均值在0 附近.
4.1.2.4 Softplus函数
Softplus 函数[Dugas et al., 2001] 可以看作Rectifier 函数的平滑版本,其定义为
Softplus 函数其导数刚好是Logistic 函数.Softplus 函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性.
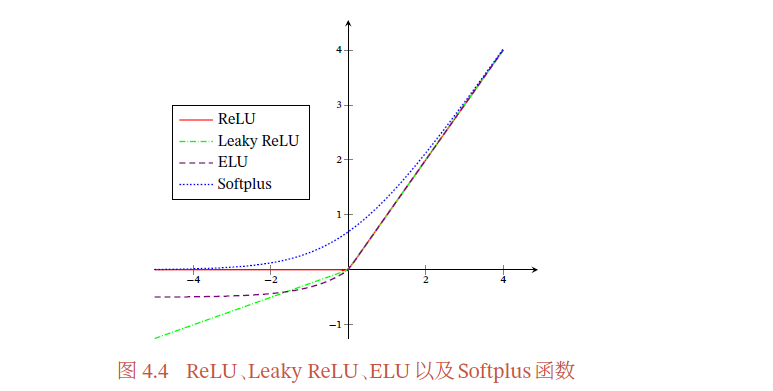
下图给出了ReLU、Leaky ReLU、ELU 以及Softplus 函数的示例
4.1.3 Swish函数
Swish 函数是一种**自门控(Self-Gated)**激活函数,定义为
swish(𝑥) = x𝜎(𝛽x)
其中𝜎(⋅) 为Logistic 函数,𝛽 为可学习的参数或一个固定超参数.𝜎(⋅) ∈ (0, 1) 可以看作一种软性的门控机制.当𝜎(𝛽𝑥) 接近于1 时,门处于**“开”状态**,激活函数的输出近似于𝑥 本身;当𝜎(𝛽𝑥) 接近于0 时,门的状态为**“关”,激活函数的输出近似于0**.
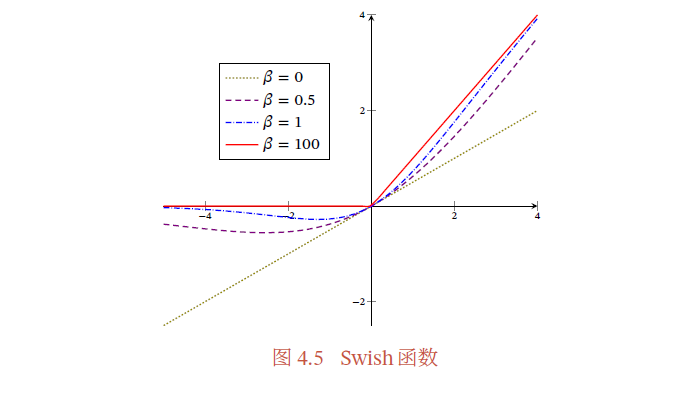
- 当𝛽 = 0 时,Swish 函数变成线性函数𝑥/2.
- 当𝛽 = 1 时,Swish 函数在𝑥 > 0时近似线性,在𝑥 < 0 时近似饱和,同时具有一定的非单调性.
- 当𝛽 → +∞ 时,𝜎(𝛽𝑥) 趋向于离散的0-1 函数,Swish 函数近似为ReLU 函数.
- 因此,Swish 函数可以看作线性函数和ReLU 函数之间的非线性插值函数,其程度由参数𝛽 控制.
4.1.4 GELU函数
GELU也是一种通过门控机制来调整其输出值的激活函数,和Swish 函数比较类似.
- 其中𝑃(𝑋 ≤ 𝑥) 是高斯分布𝒩(𝜇, 𝜎2) 的累积分布函数,其中𝜇, 𝜎 为超参数,一般设𝜇 = 0, 𝜎 = 1 即可.
- 由于高斯分布的累积分布函数为S 型函数,因此GELU 函数可以用Tanh 函数或Logistic 函数来近似,
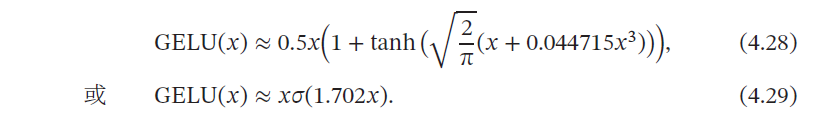
- 当使用Logistic 函数来近似时,GELU 相当于一种特殊的Swish 函数(𝛽值为1.702).
4.1.5 Maxout函数
Maxout 单元也是一种分段线性函数.Maxout 单元的输入是上一层神经元的全部原始输出,是一个向量𝒙 = [𝑥1; 𝑥2; ⋯ ; 𝑥𝐷].
每个Maxout 单元有𝐾 个权重向量 和K个偏置.对于输入𝒙,可以得到𝐾 个净输入, 1 ≤ 𝑘 ≤ 𝐾.
其中 为第𝑘 个权重向量.
然后从这个K个净输入中挑选出最大值作为输出
Maxout 单元不单是净输入到输出之间的非线性映射,而是整体学习输入到输出之间的非线性映射关系.
4.2 网络结构
要想模拟人脑的能力,单一的神经元是远远不够的,需要通过很多神经元一起协作来完成复杂的功能.这样通过一定的连接方
式或信息传递方式进行协作的神经元可以看作一个网络,就是神经网络.
到目前为止,研究者已经发明了各种各样的神经网络结构.目前常用的神经网络结构有以下三种:
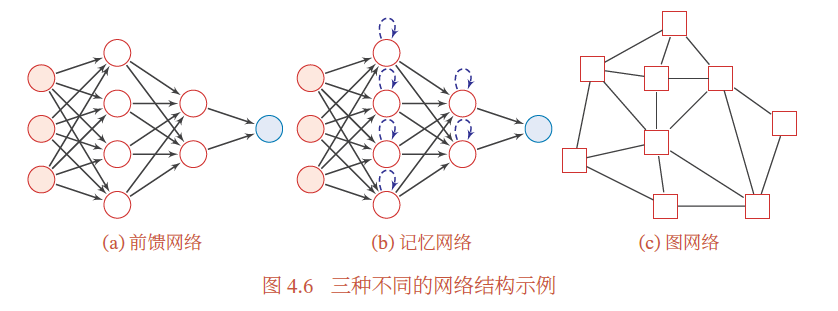
4.2.1 前馈网络
- 前馈网络中各个神经元按接收信息的先后分为不同的分组.
- 每一组可以看作一个神经层.每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元.
- 整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示.
- 前馈网络包括全连接前馈网络(本章中的第4.3节)和卷积神经网络(第5章)等.
- 前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射.这种网络结构简单,易于实现.
4.2.2 记忆网络
- 记忆网络,也称为反馈网络,网络中的神经元不但可以接收其他神经元的信息,也可以接收自己的历史信息.
- 和前馈网络相比,记忆网络中的神经元具有记忆功能,在不同的时刻具有不同的状态.
- 记忆神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示.
- 记忆网络包括循环神经网络(第6章)、Hopfield 网络(第8.6.1节)、玻尔兹曼机(第12.1节)、受限玻尔兹曼机(第12.2节)等.
4.2.3 图网络
前馈网络和记忆网络的输入都可以表示为向量或向量序列.但实际应用中,很多数据是图结构的数据,比如知识图谱、社交网络、分子(Molecular )网络等.前馈网络和记忆网络很难处理图结构的数据.
图网络是定义在图结构数据上的神经网络(第6.8节).图中每个节点都由一个或一组神经元构成.节点之间的连接可以是有向的,也可以是无向的.每个节点可以收到来自相邻节点或自身的信息.
图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如图卷积网络、图注意力网络、消息传递神经网络等.
4.3 前馈神经网络
不同的神经网络模型有着不同网络连接的拓扑结构.一种比较直接的拓扑结构是前馈网络.前馈神经网络(Feedforward Neural Network,FNN)是最早发明的简单人工神经网络.前馈神经网络也经常称为多层感知器(Multi-Layer Perceptron,MLP).但多层感知器的叫法并不是十分合理,因为前馈神经网络其实是由多层的Logistic 回归模型(连续的非线性函数)组成,而不是由多层的感知器(不连续的非线性函数)组成.
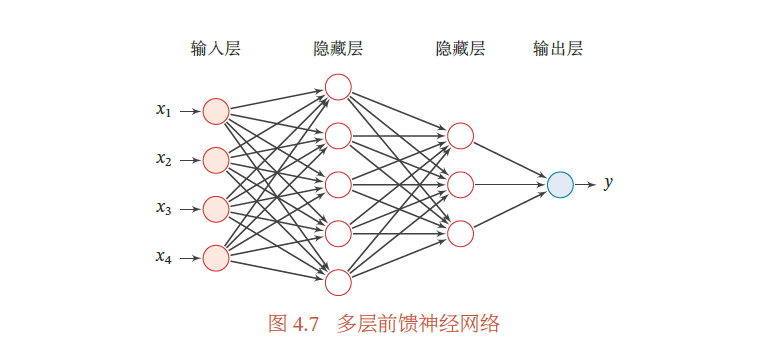
在前馈神经网络中,各神经元分别属于不同的层.
- 每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层.
- 第0层称为输入层,最后一层称为输出层,其他中间层称为隐藏层.
- 整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示.
下图给出前馈神经网络的示例
下表给出了描述前馈神经网络的数学符号
| 记号 | 含义 |
|---|---|
| 神经网络的层数 | |
| 第层神经元的个数 | |
| 𝑓𝑙 (⋅) | 第𝑙 层神经元的激活函数 |
| 第𝑙 − 1 层到第𝑙 层的权重矩阵 | |
| 第𝑙 − 1 层到第𝑙 层的偏置 | |
| 第𝑙 层神经元的净输入(净活性值) | |
| 第𝑙 层神经元的输出(活性值) |
令,前馈神经网络通过不断迭代下面公式进行信息传播:
- 首先根据第𝑙−1层神经元的活性值(Activation)𝒂(𝑙−1) 计算出第𝑙 层神经元的净活性值(Net Activation)𝒛(𝑙)
- 然后经过一个激活函数得到第𝑙 层神经元的活性值.
- 因此,我们也可以把每个神经层看作一个仿射变换(Affine Transformation)和一个非线性变换.
这样,前馈神经网络可以通过逐层的信息传递,得到网络最后的输出𝒂(𝐿).整个网络可以看作一个复合函数𝜙(𝒙; 𝑾, 𝒃),将向量𝒙 作为第1 层的输入𝒂(0),将第𝐿 层的输出𝒂(𝐿) 作为整个函数的输出.
𝒙 = 𝒂(0) → 𝒛(1) → 𝒂(1) → 𝒛(2) → ⋯ → 𝒂(𝐿−1) → 𝒛(𝐿) → 𝒂(𝐿) = 𝜙(𝒙; 𝑾, 𝒃),
其中𝑾, 𝒃 表示网络中所有层的连接权重和偏置.
4.3.1 通用近似定理

翻译一下,通用近似定理是说,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何一个定义在实数空间中的有界闭集函数
4.3.2 应用到机器学习
根据通用近似定理,神经网络在某种程度上可以作为一个**“万能”函数来使用,可以用来进行复杂的特征转换**,或逼近一个复杂的条件分布.
要取得好的分类效果,需要将样本的原始特征向量𝒙 转换到更有效的特征向量𝜙(𝒙),这个过程叫作特征抽取.
4.3.2.1 观点一
多层前馈神经网络可以看作一个非线性复合函数𝜙 ∶ ℝ^𝐷 → ℝ^{𝐷′},将输入 映射到输出𝜙(𝒙) ∈ ℝ^𝐷′.因此,多层前馈神经网络也可以看成是一种特征转换方法,其输出𝜙(𝒙) 作为分类器的输入进行分类.
给定一个训练样本(𝒙, 𝑦),先利用多层前馈神经网络将𝒙 映射到𝜙(𝒙),然后再将𝜙(𝒙) 输入到分类器𝑔(⋅),即
- 其中𝑔(⋅)为线性或非线性的分类器
- 𝜃为分类器𝑔(⋅)的参数,
- 为分类器的输出.
4.3.2.2 观点二
如果分类器𝑔(⋅) 为Logistic 回归分类器或Softmax 回归分类器,那么𝑔(⋅) 也可以看成是网络的最后一层,即神经网络直接输出不同类别的条件概率𝑝(𝑦|𝒙).
4.3.3 参数学习
对于某个样本(𝒙, 𝑦),如果采用交叉熵损失函数,其损失函数为
其中𝒚 ∈ {0, 1}𝐶 为标签𝑦 对应的one-hot 向量表示.
那么,对于给定训练集,为,将每个样本𝒙(𝑛) 输入给前馈神经网络,得到网络输出为,其在数据集上的结构化风险函数为
- 其中𝑾 和𝒃 分别表示网络中所有的权重矩阵和偏置向量;
- 是正则化项,用来防止过拟合;
- 𝜆 > 0 为超参数.𝜆 越大,𝑾 越接近于0
这里的一般使用 Frobenius 范数:
有了学习准则和训练样本,网络参数可以通过梯度下降法来进行学习.在梯度下降方法的每次迭代中,第𝑙 层的参数𝑾(𝑙) 和𝒃(𝑙) 参数更新方式为
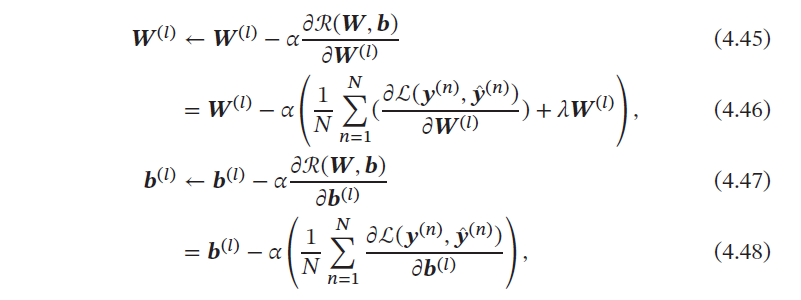
由上述公式可得,梯度下降法需要计算损失函数对参数的偏导数,如果通过链式法则逐一对每个参数进行求偏导比较低效.在神经网络的训练中经常使用反向传播算法来高效地计算梯度.
4.4 反向传播算法
使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
(1) 前馈计算每一层的净输入𝒛(𝑙) 和激活值𝒂(𝑙),直到最后一层;
(2) 反向传播计算每一层的误差项𝛿(𝑙);
(3) 计算每一层参数的偏导数,并更新参数.

偏导数\frac {𝜕L(𝒚, 𝒚̂)}{𝜕𝒛(𝑙)} 表示第𝑙 层神经元对最终损失的影响,也反映了最终损失对第𝑙 层神经元的敏感程度,因此一般称为第𝑙 层神经
元的误差项,用𝛿(𝑙) 来表示.
𝛿(𝑙) ≜ \frac {𝜕L(𝒚, 𝒚̂)}{𝜕𝒛(𝑙)} ∈ ℝ^{𝑀_𝑙}
误差项𝛿(𝑙) 也间接反映了不同神经元对网络能力的贡献程度,从而比较好地解决了贡献度分配问题(Credit Assignment Problem,CAP).
4.5 自动梯度计算
参数的梯度可以让计算机来自动计算.目前,主流的深度学习框架都包含了自动梯度计算的功能,即我们可以只考
虑网络结构并用代码实现,其梯度可以自动进行计算,无须人工干预,这样可以大幅提高开发效率.
自动计算梯度的方法可以分为以下三类:数值微分、符号微分和自动微分.
4.5.1 数值微分
数值微分(Numerical Differentiation)是用数值方法来计算函数𝑓(𝑥) 的导数.函数𝑓(𝑥) 的点𝑥 的导数定义为
要计算函数𝑓(𝑥) 在点𝑥 的导数,可以对𝑥 加上一个很少的非零的扰动Δ𝑥,通过上述定义来直接计算函数𝑓(𝑥) 的梯度.数值微分方法非常容易实现,但找到一个合适的扰动Δ𝑥 却十分困难.如果Δ𝑥 过小,会引起数值计算问题,比如舍入误差;如果Δ𝑥 过大,会增加截断误差,使得导数计算不准确.因此,数值微分的实用性比较差.
4.5.2 符号微分
符号微分(Symbolic Differentiation)是一种基于符号计算的自动求导方法。
符号计算也叫代数计算,是指用计算机来处理带有变量的数学表达式.这里的变量被看作符号(Symbols),一般不需要代入具体的值.和符号计算相对应的概念是数值计算,即将数值代入数学表示中进行计算.
符号计算的输入和输出都是数学表达式,一般包括对数学表达式的化简、因式分解、微分、积分、解代数方程、求解常微分方程等运算.
例如数学公式的化简
- 符号微分可以在编译时就计算梯度的数学表示,并进一步利用符号计算方法进行优化.
- 此外,符号计算的一个优点是符号计算和平台无关,可以在CPU 或GPU 上运行.
- 符号微分也有一些不足之处:
- 编译时间较长,特别是对于循环,需要很长时间进行编译;
- 为了进行符号微分,一般需要设计一种专门的语言来表示数学表达式,并且要对变量(符号)进行预先声明;
- 很难对程序进行调试
4.5.3 自动微分
自动微分(Automatic Differentiation,AD)是一种可以对一个(程序)函数进行计算导数的方法.符号微分的处理对象是数学表达式,而自动微分的处理对象是一个函数或一段程序.
自动微分的基本原理是所有的数值计算可以分解为一些基本操作,包含+, −, ×, / 和一些初等函数exp, log, sin, cos 等,然后利用链式法则来自动计算一个复合函数的梯度.
为简单起见,这里以一个神经网络中常见的复合函数的例子来说明自动微分的过程.令复合函数𝑓(𝑥; 𝑤, 𝑏) 为
其中𝑥 为输入标量,𝑤 和𝑏 分别为权重和偏置参数.
首先,我们将复合函数𝑓(𝑥; 𝑤, 𝑏) 分解为一系列的基本操作,并构成一个计算图(Computational Graph).计算图是数学运算的图形化表示.计算图中的每个非叶子节点表示一个基本操作,每个叶子节点为一个输入变量或常量
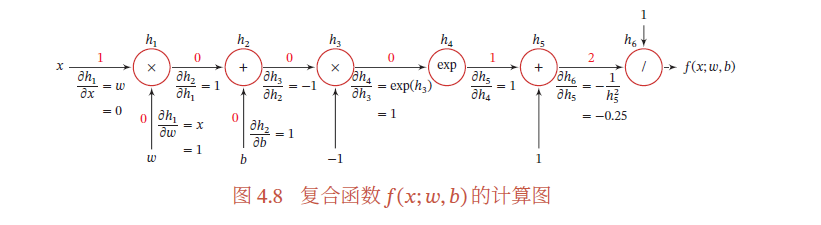
从计算图上可以看出,复合函数𝑓(𝑥; 𝑤, 𝑏) 由6 个基本函数ℎ𝑖, 1 ≤ 𝑖 ≤ 6 组成.如表4.2所示,每个基本函数的导数都十分简单,可以通过规则来实现.

整个复合函数𝑓(𝑥; 𝑤, 𝑏) 关于参数𝑤 和𝑏 的导数可以通过计算图上的节点𝑓(𝑥; 𝑤, 𝑏) 与参数𝑤 和𝑏 之间路径上所有的导数连乘来得到,即
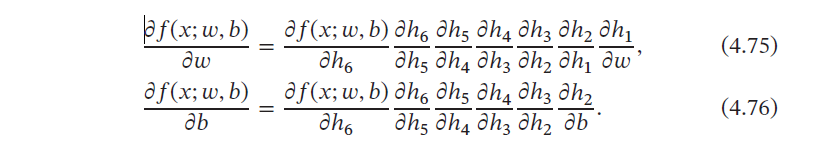
4.5.3.1 前向模式和反向模式
按照计算导数的顺序,自动微分可以分为两种模式:前向模式和反向模式.
前向模式:前向模式是按计算图中计算方向的相同方向来递归地计算梯度.

反向模式:反向模式是按计算图中计算方向的相反方向来递归地计算梯度.
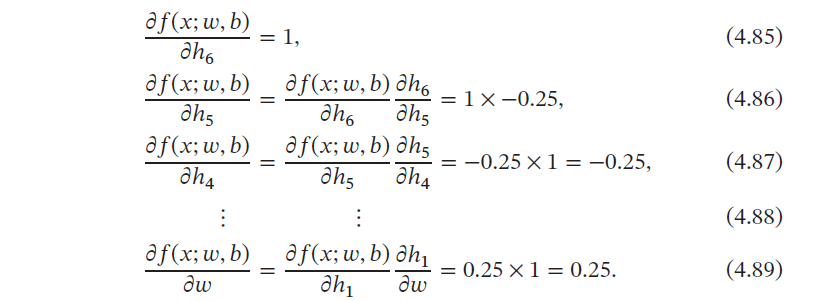
对于一般的函数形式𝑓 ∶ ,前向模式需要对每一个输入变量都进行一遍遍历,共需要𝑁 遍.而反向模式需要对每一个输出都进行一个遍历,共需要𝑀 遍.当𝑁 > 𝑀 时,反向模式更高效.在前馈神经网络的参数学习中,风险函数为𝑓 ∶ ,输出为标量,因此采用反向模式为最有效的计算方式,只需要一遍计算.
4.5.3.2 静态计算图和动态计算图
计算图按构建方式可以分为静态计算图(Static Computational Graph)和动态计算图(Dynamic Computational Graph)
静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变,而动态计算图是在程序运行时动态构建.
两种构建方式各有优缺点.
- 静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差.
- 动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高.
在目前深度学习框架里,Theano 和Tensorflow采用的是静态计算图,而DyNet、Chainer 和PyTorch 采用的是动态计算图.Tensorflow 2.0 也支持了动态计算图.
4.6 优化问题
神经网络的参数学习比线性模型要更加困难,主要原因有两点:
- 非凸优化问题
- 梯度消失问题.
4.6.1 非凸优化问题
先介绍凸和非凸区别
凸:
- 指的是顺着梯度方向走到底就 一定是 最优解 。
- 大部分 传统机器学习 问题 都是凸的。
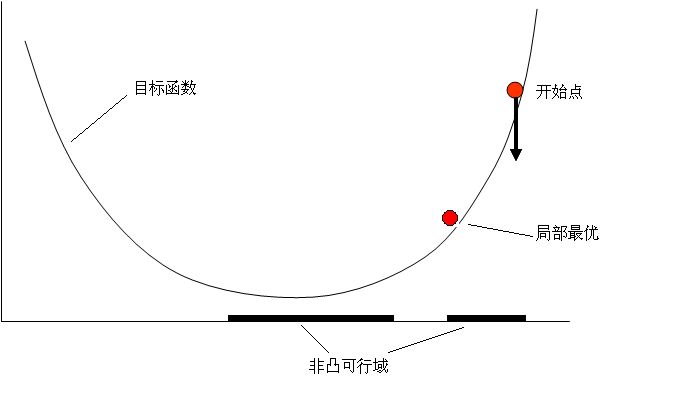
非凸:
- 指的是顺着梯度方向走到底只能保证是局部最优,不能保证 是全局最优。
- 深度学习以及小部分传统机器学习问题都是非凸的。
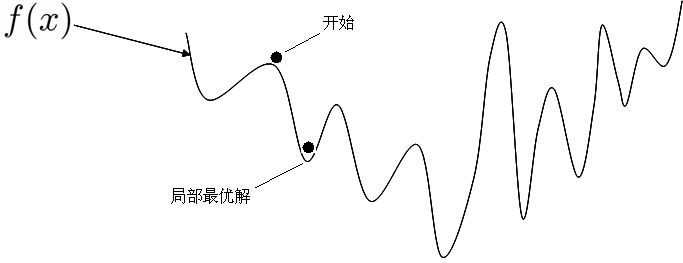
神经网络的优化问题是一个非凸优化问题
4.6.2 梯度消失问题
在神经网络中误差反向传播的迭代公式为
𝛿(𝑙) = 𝑓′_𝑙 (z^{(𝑙)}) ⊙ (𝑾^{(𝑙+1)})^T𝛿(𝑙+1).
误差从输出层反向传播时,在每一层都要乘以该层的激活函数的导数.
但是Sigmoid 型函数的导数的值域都小于或等于1,由于Sigmoid 型函数的饱和性,饱和区的导数更是接近于0.这样,误差经过每一层传递都会不断衰减.当网络层数很深时,梯度就会不停衰减,甚至消失,使得整个网络很难训练.这就是所谓的梯度消失问题(Vanishing Gradient Problem),也称为梯度弥散问题.
减轻梯度消失问题的方法有很多种.一种简单有效的方式是使用导数比较大的激活函数,比如ReLU 等.