
第8章 注意力机制与外部记忆
智慧的艺术是知道该忽视什么.——威廉·詹姆斯(William James)
根据通用近似定理,前馈网络和循环网络都有很强的能力.但由于优化算法和计算能力的限制,在实践中很难达到通用近似的能力,目前计算机的计算能力依然是限制神经网络发展的瓶颈.
神经网络中可以存储的信息量称为网络容量(Network Capacity).一般来讲,利用一组神经元来存储信息时,其存储容量和神经元的数量以及网络的复杂度成正比.要存储的信息越多,神经元数量就要越多或者网络要越复杂,进而导致神经网络的参数成倍地增加
我们人脑的生物神经网络同样存在网络容量问题,人脑在有限的资源下,并不能同时处理这些过载的输入信息.
大脑神经系统有两个重要机制可以解决信息过载问题
- 注意力
- 记忆机制
我们可以借鉴人脑解决信息过载的机制,从两方面来提高神经网络处理信息的能力.
- 一方面是注意力,通过自上而下的信息选择机制来过滤掉大量的无关信息
- 另一方面是引入额外的外部记忆,优化神经网络的记忆结构来提高神经网络存储信息的容量.
8.1 认知神经学中的注意力
注意力是一种人类不可或缺的复杂认知功能,指人可以在关注一些信息的同时 忽略另一些信息的选择能力.人脑可以有意或无意地从大量输入信息中选择小部分的有用信息来重点处理,并忽略其他信息
注意力一般分为两种:
-
自上而下的有意识的注意力:聚焦式注意力是指有预定目的、依赖任务的,主动有意识地聚焦于某一对象的注意力.
-
自下而上的无意识的注意力:基于显著性的注意力(Saliency Based Attention).如果一个对象的刺激信息不同于其周围信息,一种无意识的“赢者通吃”(Winner-Take-All)或者门控(Gating)机制就可以把注意力转向这个对象
一个和注意力有关的例子是鸡尾酒会效应. 当一个人在吵闹的鸡尾酒会上和朋友聊天时,尽管周围噪音干扰很多,他还是可以听到朋友的谈话内容,而忽略其他人的声音(聚焦式注意力).同时,如果背景声中有重要的词(比如有人提到名字),他会马上注意到(显著性注意力).
8.2 注意力机制
在计算能力有限的情况下, 注意力机制(Attention Mechanism)作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段.
在目前的神经网络模型中,我们可以将最大汇聚(Max Pooling)、门控(Gating)机制近似地看作自下而上的基于显著性的注意力机制.
除此之外,自上而下的聚焦式注意力也是一种有效的信息选择方式.
以阅读理解任务为例,给定一篇很长的文章,然后就此文章的内容进行提问.提出的问题只和段落中的一两个句子相关,其余部分都是无关的.为了减小神经网络的计算负担,只需要把相关的片段挑选出来让后续的神经网络来处理,而不需要把所有文章内容都输入给神经网络.
用 表示组输入信息,其中维向量 表示一组输入信息.为了节省计算资源,不需要将所有信息都输入神经网络,只需要从中选择一些和任务相关的信息.
注意力机制的计算可以分为两步:
- 所有输入信息上计算注意力分布
- 根据注意力分布来计算输入信息的加权平均
8.2.2 注意力分布
为了从个输入向量中选择出和某个特定任务相关的信息,我们需要引入一个和任务相关的表示,称为查询向量(Query Vector),并通过一个打分函数来 计算 每个输入向量和查询向量之间的相关性.
- 称为注意力分布 ,可以解释为在给定任务相关的查询𝒒 时,第𝑛 个输入向量受关注的程度
- 𝑠(𝒙, 𝒒) 为注意力打分函数
有以下四种注意力打分函数
-
加性模型:
-
点积模型:
-
缩放点积模型:
-
双线性模型:
其中𝑾, 𝑼, 𝒗 为可学习的参数,𝐷 为输入向量的维度.
8.2.3 加权平均
注意力分布可以解释为在给定任务相关的查询𝒒 时,第𝑛 个输入向量受关注的程度.我们采用一种“软性”的信息选择机制对输入信息进行汇总,(简单来说就是对每个输入向量的求加权平均)即
上式称为软性注意力机制(Soft Attention Mechanism).图8.1a给出软性注意力机制的示例.
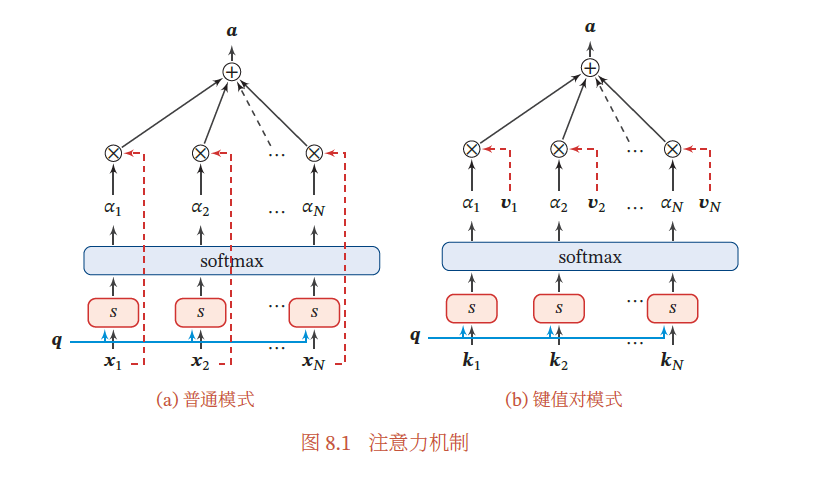
注意力机制可以单独使用,但更多地用作神经网络中的一个组件.
8.2.1 注意力机制的变体
8.2.1.1 硬性注意力
上图提到的注意力是软性注意力。此外,还有一种注意力是只关注某一个输入向量,叫作硬性注意力(Hard Attention).
硬性注意力有两种实现方式:
- 选取最高概率的一个输入向量
- 通过在注意力分布式上随机采样的方式实现
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息,使得最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练.因此,硬性注意力通常需要使用强化学习来进行训练.为了使用反向传播算法,一般使用软性注意力来代替硬性注意力.
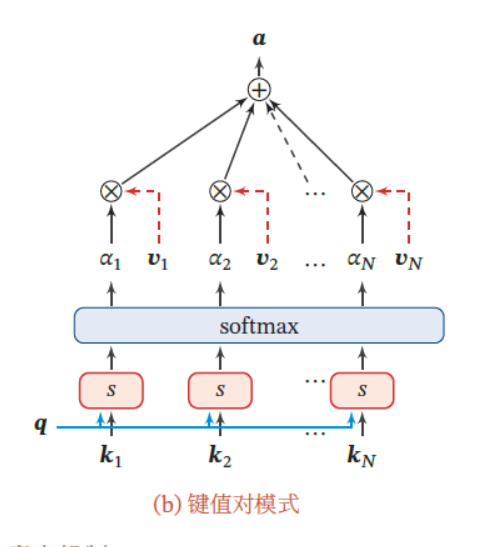
8.2.1.2 键值对注意力
我们可以用键值对(key-value pair)格式来表示输入信息
- 其中“键”用来计算注意力分布𝛼_𝑛
- “值”用来计算聚合信息.
用$(K, V) = [(𝒌_1, 𝒗_1), ⋯ , (𝒌_N , 𝒗_N )] $表示𝑁 组输入信息,给定任务相关的查询向量𝒒 时,注意力函数为
att((𝑲, 𝑽), 𝒒) = \sum ^𝑁 _{𝑛=1} 𝛼_n𝒗_n = \sum ^𝑁 _{𝑛=1} \frac {exp(𝑠(𝒌_𝑛, 𝒒))} {\sum _j exp (𝑠(𝒌𝑗 , 𝒒))}𝒗_𝑛
其中 为打分函数,.当𝑲 = 𝑽 时,键值对模式就等价于普通的注意力机制.
8.2.1.3 多头注意力
多头注意力(Multi-Head Attention)是利用多个查询,来并行地从输入信息中选取多组信息.每个注意力关注输入信息的不同部分.
其中表示向量拼接
8.2.1.4 结构化注意力
在之前介绍中,我们假设所有的输入信息是同等重要的,是一种扁平结构,注意力分布实际上是在所有输入信息上的多项分布.但如果输入信息本身具有层次结构,比如文本可以分为词、句子、段落、篇章等不同粒度的层次,我们可以使用层次化的注意力来进行更好的信息选择.此外,还可以假设注意力为上下文相关的二项分布,用一种图模型来构建更复杂的结构化注意力分布
8.2.1.5 指针网络
注意力机制可以分为两步:
- 一是计算注意力分布,
- 二是根据来计算输入信息的加权平均.
我们可以只利用注意力机制中的第一步,将注意力分布作为一个软性的指针(pointer)来指出相关信息的位置.
指针网络是一种序列到序列模型,输入是长度为𝑁 的向量序列,输出是长度为𝑀 的下标序列
和一般的序列到序列任务不同, 这里的输出序列是输入序列的下标