卷二 01|一次请求怎么进入 Claude Code 的主循环¶
导读¶
- 所属卷:卷二:用户输入怎么变成一次完整的 agent turn
- 卷内位置:01 / 08
- 上一篇:卷一 03|一次请求是怎么跑成一次 Agent Turn 的
- 下一篇:卷二 02|用户输入在进入运行时之前经历了什么
卷一第 3 篇已经立过一张低分辨率的动态闭环图:输入进入运行时,系统形成当前判断,必要时调用能力,结果回流,再决定继续还是收口。
但到了卷二,这张图还不够用。因为卷二不再满足于说“它会这样跑”,而是要开始回答:
一条用户请求进入 Claude Code 之后,整条主线到底是怎样真正展开的?
这篇作为卷二总起篇,只做一件事:
先把“一次请求怎么进入主循环”的总图立起来。
先把时间顺序看清,再把后面几篇分别拆哪一步交代清楚。
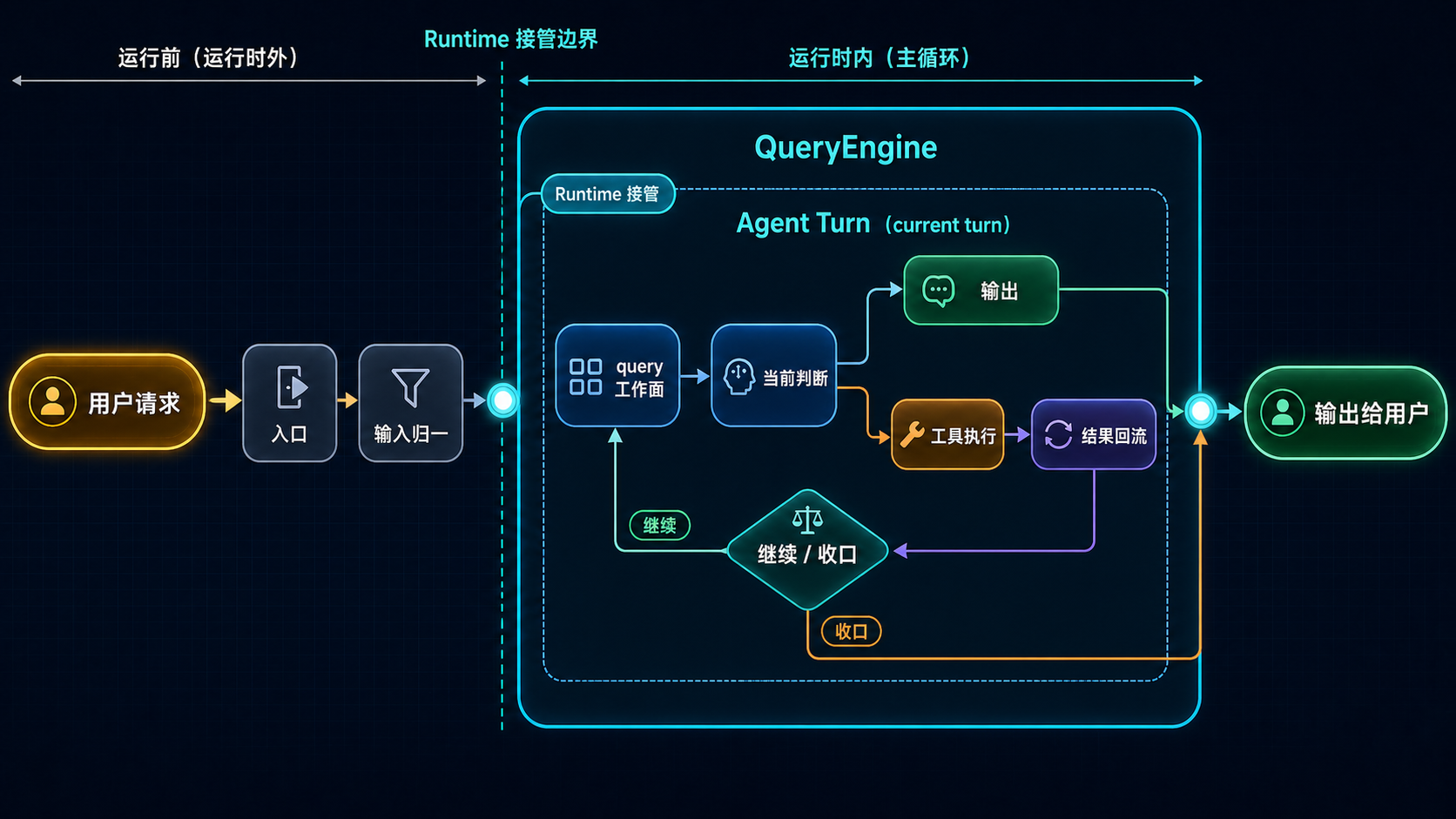
图:用户请求不是被直接丢给模型,而是先被接入主循环,沿着输入归位、QueryEngine、当前 query、执行与结果回流一路推进。
先给判断:进入主循环,不是把一句话交给模型,而是把一次请求接成一条可持续推进的工作链¶
卷一第 03 篇已经讲清了:Claude Code 的基本单位不是“回一句话”,而是一轮会继续推进的 agent turn。
卷二第 01 篇不再把这条闭环完整重讲一遍,只往前推进一步:
Claude Code 的主循环不是“收输入、回输出”的单步过程,而是一条把请求接入运行时、形成当前判断、触发能力、接回结果并持续推进的工作链。
这篇真正要立住的,不是“入口函数在哪里”,而是:
一次请求进入 Claude Code 之后,会被接成一条持续推进的主循环时间线。
先看整条时间线:一次请求进入主循环之后,会经过哪几步¶
先把细节都压住,只看卷二需要读者记住的总图。
flowchart TD
U[用户输入] --> P[输入预处理与归位]
P --> E[请求进入 QueryEngine]
E --> Q[组织当前 query 工作面]
Q --> J[形成当前判断]
J --> D{直接回答\n还是触发能力?}
D -- 直接回答 --> A[形成本轮输出]
D -- 触发能力 --> T[发起 tool use / action]
T --> X[执行能力]
X --> R[结果回流当前 turn]
R --> C{继续\n还是收口?}
C -- 继续 --> Q
C -- 收口 --> A
A --> O[输出给用户]这张图里最重要的,不是节点名字,而是时间顺序。
也可以把它和卷一第 03 篇的闭环图区分得更直白一点:
卷一讲的是“为什么它会形成闭环”,卷二这张图讲的是“这条闭环在主循环里按什么时间顺序正式展开”。
卷二接下来要做的,就是沿着这条顺序往下拆:
- 输入先怎么被整理和归位
- 请求怎样真正进入 QueryEngine
- 当前 query 怎样被组织成一个工作面
- 系统怎样形成“这一轮下一步该做什么”的判断
- 执行结果怎样重新回到当前 turn
- 一轮 turn 什么时候继续,什么时候收口
换句话说,卷二不是组件词典,而是一条按时间顺序展开的运行线。
从源码角度看,这一篇只先钉住“入口对象”,不展开入口层次¶
卷二这一篇不深挖源码,但也不能完全飘在概念上。这里先只钉住一个足够支撑总图的判断:
请求不是直接撞进模型,而是先被接进
QueryEngine这样一个持续存在的 turn 级运行对象。
QueryEngine.ts 里有一句很关键的注释:
One QueryEngine per conversation. Each submitMessage() call starts a new turn within the same conversation.
这句话先帮卷二总起篇立住三件事:
QueryEngine不是一次性问答函数- 它对应的是一段持续存在的 conversation
- 每次新请求进入时,系统处理的不是裸文本,而是一轮新的 turn
所以这篇只需要先把读者带到这里:
一次请求进入 Claude Code,不是进入一次孤立调用,而是进入一个会持续维护 messages、状态与运行约束的主循环世界。
至于更细的问题,比如:
- 为什么真正入口要落在
submitMessage(...) query(...)和入口对象是什么前后层次- 输入在入口前后分别如何被装配
这些都留给卷二第 03 篇单独展开。
主循环推进的单位,其实是当前 turn¶
从聊天视角看,一次请求的终点像是一句回复;但从运行时视角看,真正被推进的是当前 turn。
所以卷二真正想建立的,不是“Claude Code 会调用工具”,而是:
Claude Code 会把一次请求接成一个可持续推进的 current turn。
卷二后文会沿这条线继续拆¶
后面几篇会顺着这张总图往下走:
- 第 2 篇讲进入运行时之前的输入前站
- 第 3 篇讲请求怎样真正进入 QueryEngine
- 第 4 篇讲当前 query 工作面怎样被组织起来
- 第 5 篇讲这一轮怎样形成“要不要调用能力”的当前判断
- 第 6 篇讲执行结果怎样重新回到当前 turn
- 第 7 篇讲这一轮什么时候继续,什么时候收口
这篇只先立总图,不深挖卷三的执行层细节,也不展开卷四的上下文治理细节;它借 QueryEngine.ts 锚定入口,但目标不是做文件导读,而是先把主循环时间线立住。
一句话收口¶
卷二要先立住的,不是某个组件,而是一次请求进入 Claude Code 主循环后的整条时间线:请求先被整理并接入运行时,再形成当前 query 工作面与当前判断,必要时触发能力,把结果接回当前 turn,最后决定这一轮继续还是收口。只有先留下这张总图,后面几篇才不会散成一堆局部机制。